无监督学习可预训练,OpenAI第一篇论
ChatGPT再次进化,迎来大更新和大降价。
当地时间6月13日,OpenAI宣布对其大型语言模型API(包括GPT-4和GPT-3.5-turbo)进行重大更新,包括新增函数调用功能、降低使用成本等多项内容。更新后,嵌入式模型成本下降75%,同时为GPT-3.5-turbo增加了16000(此前为4000)的输入长度。主要更新内容:· 在Chat Completions API 中增加了新的函数调用能力;· 推出新版本GPT-4-0613和GPT-3.5-turbo-0613模型;· GPT-3.5-Turbo上下文长度增长4倍,从4k增长到16k;· GPT-3.5-Turbo输入token降价25%;· 最先进embeddings model降价75%;· 公布GPT-3.5-Turbo-0301 和 GPT-4-0314 模型的淘汰时间表。本次更新中,备受关注的是函数调用能力。据华尔街见闻报道,开发者现在可以向GPT-4-0613和GPT-3.5-turbo-0613两个模型描述函数,并让模型智能地选择输出一个包含参数的JSON(JavaScript Object Notation,一种数据交换的文本格式)对象,来调用这些函数。若将GPT功能与外部工具或API进行连接,这种方法更加可靠。也就是说,GPT不再需要开发者描述复杂的提示语,它自己能够决定是否动用外部工具来解决问题,不仅显著提高了反应速度,还大大降低了出错的可能性。此外,OpenAI发布的降价消息也让不少用户为之欢呼。官网公告显示,不同版本降价幅度不同,OpenAI最先进、用户最多的嵌入模型Text-embedding-ada-002降价75%;用户最多的聊天模型GPT-3.5-turbo降价25%。OpenAI首席执行官Sam Altman此前在新加坡管理大学演讲时表示,OpenAI每三个月左右就能将推理成本降低90%,未来将继续大幅削减成本。人工智能时代正在到来。ChatGPT作为一个窗口,让我们得以提前窥见AI世界。本文对ChatGPT的基本技术原理进行了分析和解读,可供读者学习和参考,推荐阅读。作者简介:浙江大学信电学院副教授,2002年清华大学电子工程系专业本科毕业,2007年英国南安普敦大学电子与计算机工程系博士毕业,博士期间的研究方向是人脸识别和说话人识别的融合算法。2007-2009 年在比利时鲁汶大学通信与遥感实验室从事博士后研究工作,研究方向为三维网格数字水印。2009 年12 月起为浙江大学信息与电子工程学院讲师,2013年晋升副教授并担任信息与通信工程系副系主任。目前主要研究方向为计算机视觉、机器学习、深度网络模型压缩和加速等。在国际顶级期刊和会议上发表论文70多篇,包括TIP, PR, AAAI, CVPR等,主持多项国家和省级科研项目。他的机器学习视频课程在BILIBILI网站上获得超过100万点击量。本文为胡浩基教授在全球数字金融中心(杭州)举行的“科技向善:强AI时代的变革”人工智能与数字金融研讨会发言。

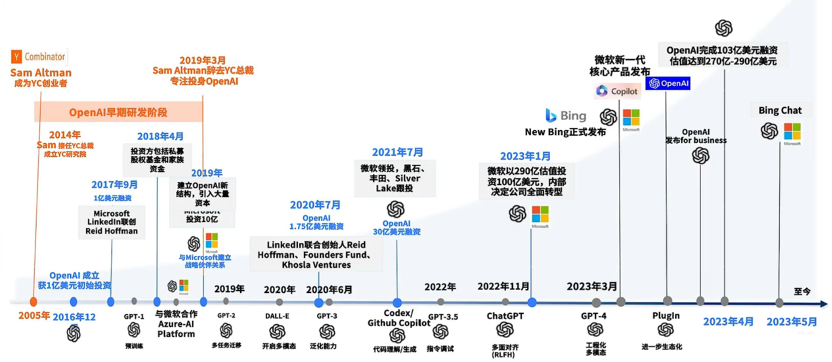
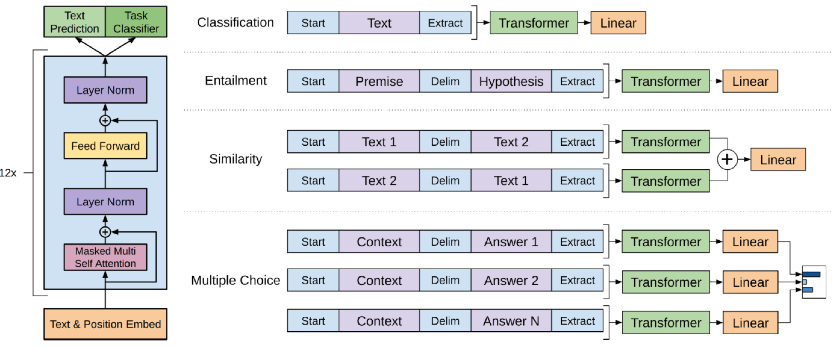
ChatGPT是由Open AI公司在2022年11月推出的大规模语言模型,它的发展历史如下图所示。ChatGPT的英文全称叫Chat Generative Pre-trained Transformer,翻译成中文就是 — 聊天的、生成的、预训练的Transformer网络。接下来,我们把chatGPT的这几个词,一个一个的详细讲解具体的意思是什么。
Transformer网络
首先讲一下Transformer网络,在2013年左右深度学习刚起来的时候,那个时候最主要的网络结构叫做卷积神经网络,Covolutional Neural Networks,或者叫做CNN。在2017年左右的时候,Google推出了Transformer网络。
由于CNN是一个过于层次化的结构,因此在CNN最开始的几层只能看到数据的局部情况,而看不到整个数据的全局情况,所以Google推出了基于注意力机制(Attention Mechanism)的Transformer网络,使网络在最初的几层也能看到这整个数据的全局信息。
至于为什么叫Transformer网络,据我考证,那时因为那个时候正好在放映电影变形金刚5(Transformer 5)。这张图中分别给出了是CNN和Transformer的网络结构,同时我们也给出了CNN和Transformer网络特点之间的一些对比。
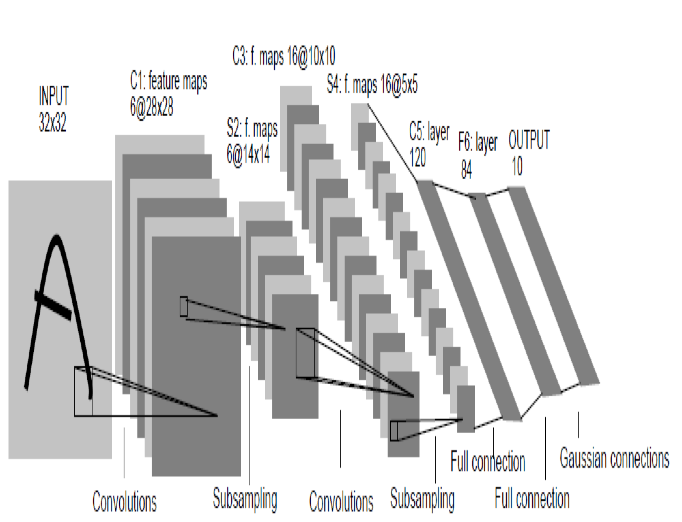
“传统的”卷积神经网络(Convolutional Neural Networks, CNN)基本结构图
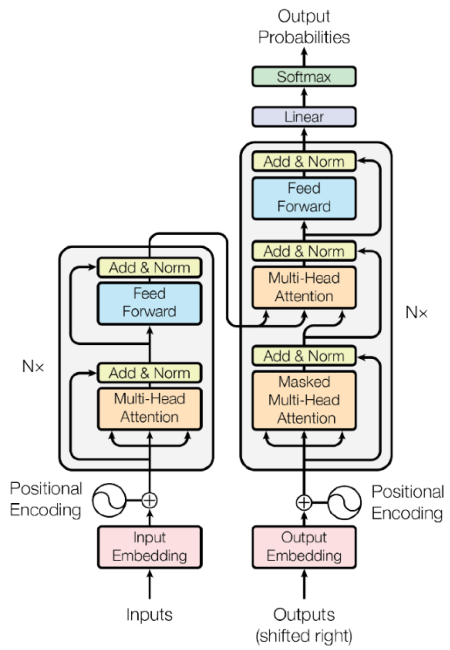
Transformer网络基本结构图
CNN与Transformer特点对比

参考文献
(1) LeCun Y., Bottou L., Bengio Y., and Haffner P., Gradient-based learning applied to document recognition, Proceedings of the IEEE, pp. 1-7, 1998 (深度学习创始人之一Yann LeCun在1998年首次提出现在使用的卷积神经网结构).
(2) A. Vaswani et al., Attention is all you need, in NIPS2017, pp. 1-11, 2017 (Google在人工智能顶级会议NIPS上发表的论文首次提出了Transformer网络结构).
在2019年左右,Google把Transformer应用在自然语言处理的各种任务上。例如,最早基于Transformer的BERT模型,将Transformer应用在自然语言处理上,获得很大成功。因此,从2019年起,自然语言处理这个领域就基本上确定了Transformerer比CNN更好。
在另外的领域,例如计算机视觉,什么时候我们才真正的觉得Transformer比CNN好呢?这个时间大概是在2021年,相对来说晚了两年。这里是微软亚洲研究院的一篇论文,它提出了Swin Transformer。人类的视觉是有层级的,而Transformer这种过于并行化的网络结构打破了视觉的层级,因此Transformer在计算机视觉领域的效果不好。
Swin Transformer对传统的Transformer进行了改进,我个人的观点是,Swin Transformer吸收了CNN中的分层结构并有效融入到传统的Transformer当中,形成了一个“CNN+Transformer”的模型,使得Transformer在视觉任务中的效果有了明显提升。所以说Transformer从2021年开始,逐渐取代了CNN成为人工智能领域的主流网络。
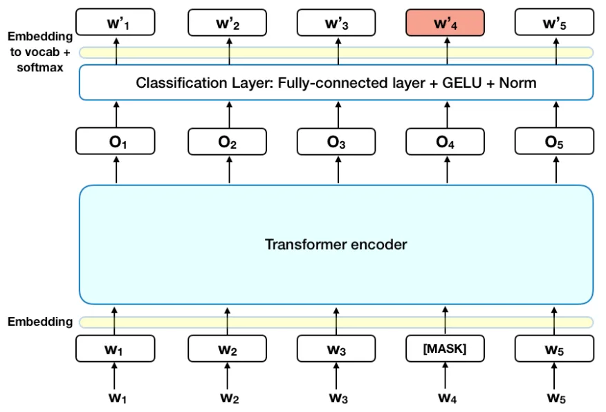
BERT是较早将Transformer用在自然语言处理的成功模型
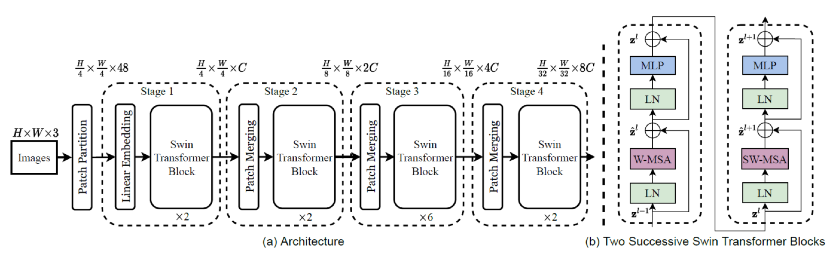
Swin Transformer是将Transformer用在计算机视觉领域的成功模型
参考文献(1) J. Devlin, M. –W. Chang, K. Lee and K. Toutanova, BERT: Pretraining of Deep Bidirectional Transformers for Language Understanding, in NAACL-HLT 2019, pp. 4171–4186, 2019. (BERT将Transformer网络应用于自然语言理解中,在多个自然语言处理任务上获得很好效果,这一研究成果推动了charGPT的出现).(2) Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin and B. Guo, Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows, in ICCV 2021, pp. 1-14, 2021 (Transformer在计算机视觉领域的表现不够好,直到2021年微软亚洲研究院的这篇Swin Transformer,将CNN的一些结构和Transformer结合,终于获得了很好的效果,这一研究成果推动了Transformer在计算机视觉领域的普及).从2021年开始,我们实验室也基于Transformer也做了一些工作,尤其是在医学图像处理领域。如下是我们基于Transformer对二维乳腺自动超声肿瘤图像和三维牙齿口扫图像进行分割,获得了很好的结果。
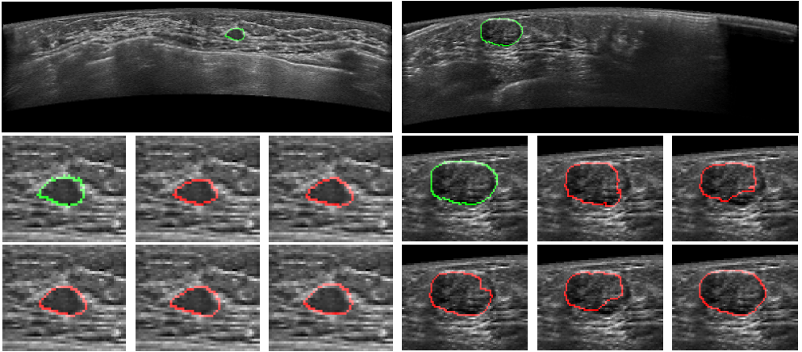
(a)乳腺自动超声肿瘤分割
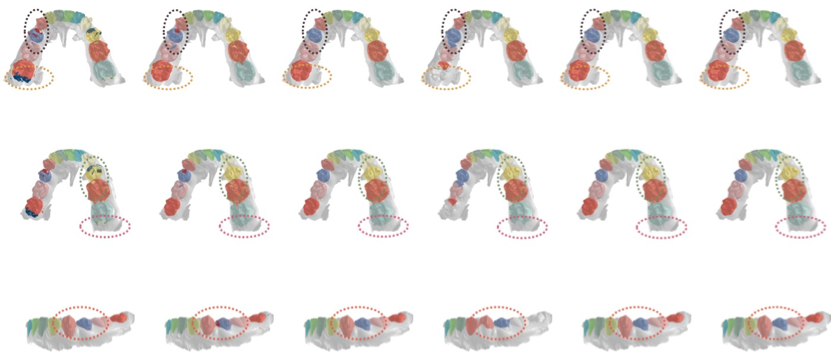
(b)三维牙齿口扫图像的分割
我们实验室的工作将Transformer应用于医学图像处理的工作
参考文献:
(1)Xiner Zhu, Haoji Hu, Hualiang Wang, Jincao Yao, Wei Li, Di Ou, Dong Xu, Region Aware Transformer for Automatic Breast Ultrasound Tumor Segmentation, in Medical Imaging with Deep Learning, MIDL2022, Zürich, Switzerland, pp. 1-15, 2022.
(2)Zuozhu Liu, Xiaoxuan He, Hualiang Wang, Huimin Xiong, Yan Zhang, Gaoang Wang, Jin Hao, Yang Feng, Fudong Zhu, Haoji Hu, Hierarchical Self-supervised Learning for 3D Tooth Segmentation in Intra-oral Mesh Scans, IEEE Transactions on Medical Imaging, vol. 42, no. 2, pp.467-480, 2023.
关于Pre-trained 预训练
接下来我们讲第二个词– Pre-trained,即预训练。预训练是什么意思呢?一般来说计算机进行的是监督学习。例如这张图中,以英文翻译中文为例,输入“I eat an apple”,输出是“我吃苹果”。接着输入“You eat an orange”,输出是“你吃橘子”。当有很多输入时,我们可以设计算法,让计算机自动发现 “I”可能对应“我”;“You”对应“你”;“Apple”对应“苹果”;“Orange”对应“橘子”。以上就是用监督学习的方式教计算机英文翻译中文的例子。
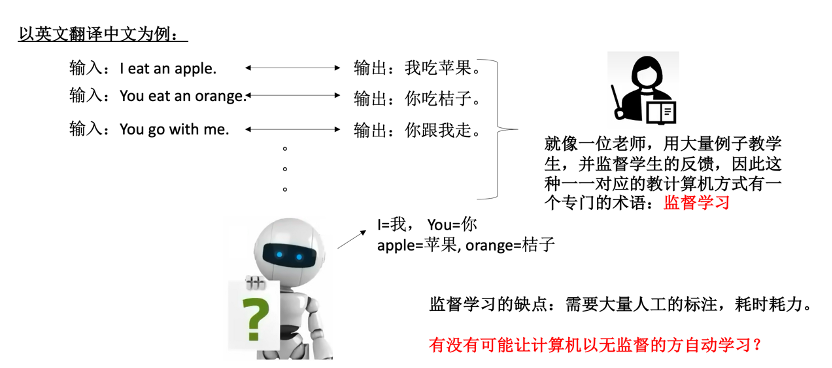
监督学习在数据标注方面存在一个问题,需要大量的人工标注,耗时耗力。为了解决这个问题,人们提出了使用无监督、没有标注的数据来进行学习的方法,这就是预训练技术。Open AI在2020年发表了关于预训练的第一篇论文,展示了这种方法的可行性。在准备演讲的PPT时,我忘记了这篇论文的具体名字。于是我询问了chatGPT,它直接告诉我了该论文的名称。我强烈建议大家在使用预训练技术时,好好利用chatGPT,它确实是一个非常有用的工具。
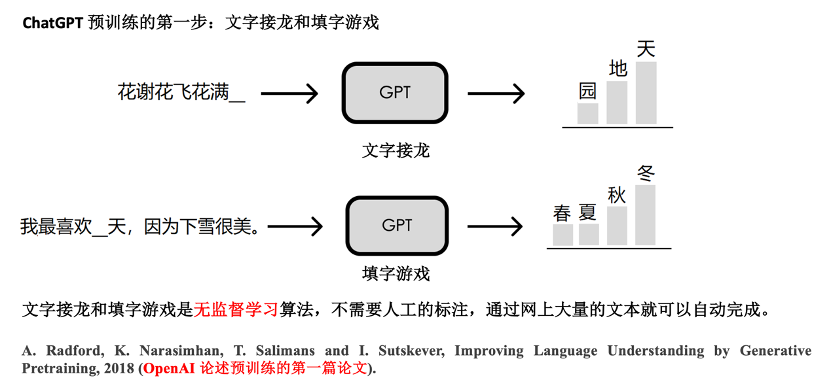
Open AI做的预训练大致是什么意思呢?首先它玩两个游戏,一个叫做文字接龙,一个叫做填字游戏。文字接龙就是给计算机一段文字,让计算机猜后面的一个字或者一个词是什么,这样的方式就不需要人工去标注这段文字了。第二个游戏就是填字游戏,比如我把中间的字隐去,让计算机根据整个语句环境猜中间的一个字是什么,填字游戏也不需要人工去标注文字。
因此,利用预训练,就可以完全利用整个互联网没有标注的各种各样的数据来做这样的文字接龙和填字游戏。所以,可以用于预训练的数据非常多。利用预训练,我们可以获得一个ChatGPT的“初步大脑”。
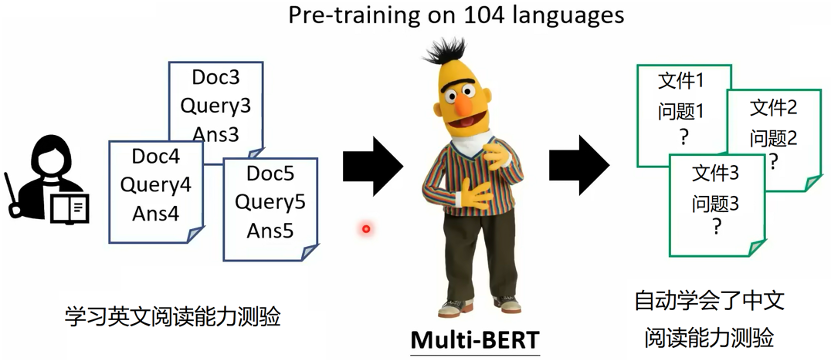
接下来可以通过特定的任务来微调这个“初步大脑”,比如说在如下论文中,首先在104种语言的网站上进行预训练。经过预训练后,用一个相对少的有标注的数据进行微调,实验表明,经过预训练后,用这么少的数据进行微调就能够得到非常好的结果。这就像我们人脑,经过了大量基础知识的学习后,只要稍微用一点点专业知识来“微调”,就能学会那些专业知识了。
接下来我们讲预训练带来的两个“魔法”。第一个叫做触类旁通。例如,在我们用104种语言做预训练后获得了一个初步的模型。然后我们只用少量的英文数据做阅读能力测验训练,前面说过,这个经过预训练的模型很快就学会了做英文阅读能力测验。
更令人吃惊的事情是,我们完全没有用中文对模型进行微调,但这个模型在学会英文阅读能力测试的同时,自动也就会了中文阅读能力测试!换句话说,预训练能够将一种语言上的任务迁移到另外的语言上去。这是因为我们针对各种语言进行了预训练,因此chatGPT学到了各种语言的隐含关系,所以它就能够根据这样的隐含关系,把在一个语言上的任务迁移到另外的语言上去。
预训练的魔力之二,就是刚才张岩老师讲的涌现能力,随着模型和数据增加到一定的地步了,整个模型的能力会快速的增长。由于张老师很详细的讲到了这一点,我就不再赘述了。
除了预训练之外,ChatGPT还用了一个关键技术,叫做强化学习。这是OpenAI描述ChatGPT中如何进行强化学习的论文– Reinforcement Learning with Human Feedback (RLHF)。翻译过来就是,带有人类反馈的强化学习。它大概说的是什么意思?
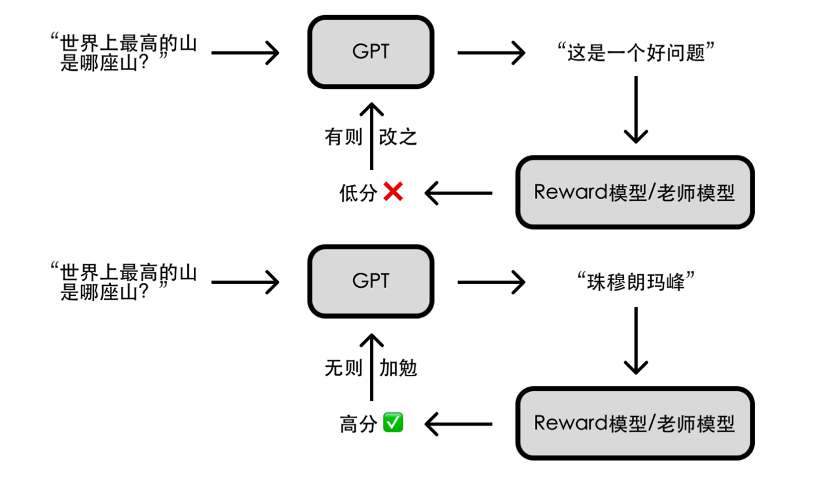
当我们经过了预训练,经过了具体任务的微调还是不够的,我们要把人的价值观展现给计算机。人对于什么文章是好的,什么文章是不好的,需要加以评判,并把这个评判结果告诉计算机,这样计算机就能生成人类觉得好的文章。比如说,你问“世界上最高的山是哪一座?”,GPT有可能接下面一句话,“这是一个好问题”。这个答案虽然逻辑是通的,但是它的回答是不好的。因此我们需要有一个人类的老师来监督,对好的回答给个高分,对不好的回答给个低分。比如说,你问“世界上最高的山是哪一座?”如果回答是“珠穆朗玛峰”,那么要给一个高分;而如果回答“这是一个好问题”,就要给个低分。OpenAI公司内部有一套详细的实训手册,就是要统一告诉进行标注的人类老师什么答案是好的,什么答案是不好的。它要有一个非常统一的对于好和不好答案的认识,这样才能让训练变得更加的统一,容易收敛。
讲完ChatGPT的基本原理后,接下来我们讲一下对ChatGPT的评价。张岩老师的PPT里面讲到很多好的评价,所以我要讲一点点不好的评价。
第一个评价来自深度学习创始人之一Yann LeCun。“ChatGPT提供支持的大型语言模型并不是什么新鲜事,所用的技术在ChatGPT出现之前已经存在多年了”。这句话当然是对的,但是我觉得如果说能够把已有的技术组合起来,达到现在的技术没有达到的一个新高度,我个人认为就是“新鲜事”。下面这句话我觉得比较关键,“ChatGPT不知道世界的存在。它们对物理现实一无所知,它们没有任何背景知识,它们找不到答案,它们经常产生令人信服的废话”。
另外一个不好的评价来自语言学家乔姆斯基,他对比了ChatGPT和人脑之间的区别说:“人脑不像ChatGPT及其同类产品那样,是一个笨重的模式匹配统计引擎,狼吞虎咽地处理数百兆字节的数据,并推断出最为可能的对话回应。人类的大脑是一个极为高效甚至优雅的系统,只需要少量的信息即可运作;它寻求的不是推断数据点之间的粗暴关联,而是创造解释。”目前的深度学习,包括ChatGPT运用的这种基于统计的学习方式,在语言学家乔姆斯基看来与我们人类大脑的运作是背道而驰的。
相关思考
最后讲一些我对ChatGPT的思考。网上已经有了各种人的各种思考了,基本把能够说的话都说完了,因此思考得有新意还是比较困难的。我想了三个相对有新意的点,分享给大家。
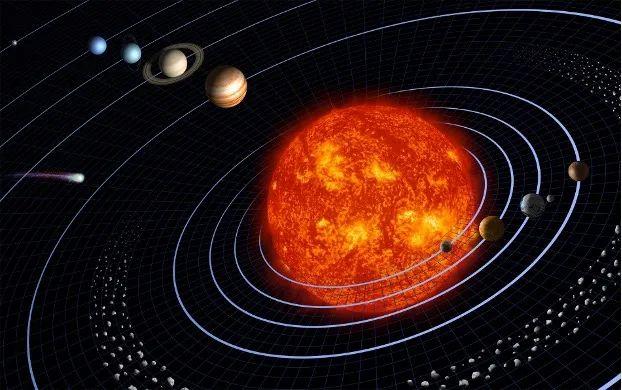
第一个思考,世界的规律到底是简单的还是复杂的?我们小时候学到牛顿力学和万有引力定律,用几个公式来总结和解释世界的规律。但是从深度学习开始,以ChatGPT为代表的深度模型逐渐占据统治地位后,我们将那么多数据扔进一个那么多参数的大模型中,我们已经完全不能理解和把握这个大模型的内在规律了。
这个世界的规律真的复杂到需要我们创造一个大模型去描述它吗?还是说世界的规律仍然是简单的,我们目前只是欠缺认识这种简单规律的能力?未来人类的科学研究是否还可能回到以前那种寻找简单规律的模式呢?下面的第一张图说明,牛顿力学和万有引力定律把太阳和行星的运动描绘得那么准确,而它用的只是几个数学公式而已,这与现在以深度学习为代表的那种人工智能是完全背道而驰的。
第二个思考,人类的语言是无限创造力和发展可能性的源泉,还是人工智能可以穷尽的符号的排列组合?在这里,我想起了高中语文的课文《最后一课》,语言是一个民族的骄傲,也是我们人类的创造力源泉。如果离开了语言,我们将没有文学、艺术,诗歌和音乐,也没有进行任何思考的工具。但是,现在ChatGPT用这种粗暴的统计手段,将语言变成了符号的排列组合问题,那么人作为一种主体,尊严何在?一个重要的问题是,ChatGPT所生成的那些文字,是否跟人类产生的文字有本质的区别呢?如果有区别,发现并找出这种区别,是有关人类生存尊严的重要问题。
第三个思考是关于经济和金融领域。今天是一个经济和金融的论坛,我想和大家讨论在公司创业过程中“利”和“义”的关系问题。Open AI这家公司自称是一个非盈利机构,公司的目标是实现通用的人工智能以便造福人类社会。当然,他们这样说,不见得会这样做。这里我想到,在2019年我去参加一个人工智能大会NeurIPS的时候,大会请了一个美国开公司的女性CEO做报告,这个CEO明确的说,我们公司不追求利润,也不追求上市,我们的目标是为了在全人类实现公平。这是一张她解释平等和公平区别的图,平等是给每一个人一个小板凳,而公平是给那些矮的人两个小板凳,而对那些高的人就不要给他小板凳了。
以上话题涉及到经济和金融政策,也涉及到价值判断,这些领域我都不是专家,因此我很想听一下大家的见解,和大家一起共同学习进步。
End.往期推荐这里有一份数字人才的就业地图137部数字经济政策,透露了什么信号?三大互联网巨头的云计算盘点隐私计算九问!涉及断直连、ChatGPT以App为支点,宇宙行进击AGI时代蓝色的支付宝,底层越来越“绿”零售业务运营突围,银行表情包走“心”
转载、合作、交流请留言,
数据与商业合作:13261990570(微信同号)
客服微信:lycj002
来个“分享、点赞、在看、设为星标”?ChatGPT再次进化,这次迎来了大更新和大降价。当地时间6月13日,OpenAI宣布对其大型语言模型API(包括GPT-4和GPT-3.5-turbo)进行重大更新,包括新增函数调用功能、降低使用成本等多项内容。更新后,嵌入式模型成本下降75%,同时为GPT-3.5-turbo增加了16000(此前为4000)的输入长度。
主要更新内容:
· 在Chat Completions API 中增加了新的函数调用能力;
· 推出新版本GPT-4-0613和GPT-3.5-turbo-0613模型;
· GPT-3.5-Turbo上下文长度增长4倍,从4k增长到16k;
· GPT-3.5-Turbo输入token降价25%;
· 最先进embeddings model降价75%;
· 公布GPT-3.5-Turbo-0301 和 GPT-4-0314 模型的淘汰时间表;
本次更新中,备受关注的是函数调用能力。据华尔街见闻报道绍,开发者现在可以向GPT-4-0613和GPT-3.5-turbo-0613两个模型描述函数,并让模型智能地选择输出一个包含参数的JSON(JavaScript Object Notation,一种数据交换的文本格式)对象,来调用这些函数。若将GPT功能与外部工具或API进行连接,这种方法更加可靠。
也就说,GPT不再需要开发者描述复杂的提示语,它自己能够决定是否动用外部工具来解决问题,不仅显著提高了反应速度,还大大降低了出错的可能性。
此外,OpenAI发布的降价消息也让不少用户为之欢呼。官网公告显示,不同版本降价幅度不同,OpenAI最先进、用户最多的嵌入模型Text-embedding-ada-002降价75%;用户最多的聊天模型GPT-3.5-turbo降价25%。OpenAI首席执行官Sam Altman此前在新加坡管理大学演讲时表示,OpenAI每三个月左右就能将推理成本降低90%,未来将继续大幅削减成本。
从战胜全球顶尖棋手的 AlphaGo 到 OpenAI 创造的大语言模型 ChatGPT,人工智能正在一步一步地解构人类的思考逻辑和语言模式。
关键词:监督学习,人工标注,预训练技术,Open AI,第一篇论文,ChatGPT。