Alpaca-LoRA:降低微调ChatGPT模型需求的创新方法
文章主题:关键词:Alpaca-LoRA, ChatGPT, 微调
在科技迅速发展的当下,我们很高兴地宣布,Alpaca-LoRa技术已经将微调类ChatGPT模型的算力需求降低到消费级的水平。这一突破性的成果意味着,我们可以更容易地训练自己的中文对话模型,从而在人工智能领域取得重要进展。这一创新技术的出现,无疑将为广大研究和应用场景带来巨大的影响和价值。
2023 年,聊天机器人领域似乎只剩下两个阵营:「OpenAI 的 ChatGPT」和「其他」。
ChatGPT 的功能确实相当出色,然而 OpenAI 却不太可能将其开源。尽管「其他」阵营的表现略显逊色,但仍有许多人在努力推动开源项目的发展,例如 Meta 最近开源的 LLaMA。
LLaMA 是一个包含多种不同规模模型的术语,这些模型的参数量从 70 亿到 650 亿不等。在所有这些模型中,LLaMA 模型以其出色的表现脱颖而出,它在大多数基准测试中超越了参数量高达 1750 亿的 GPT-3。然而,值得注意的是,这种卓越的表现并未通过指令微调(instruction tuning)来实现,这可能导致其在生成效果方面存在一定的不足。
为提升模型表现,来自斯坦福的研究团队协助完成指令微调任务,并创建了一个名为Alpaca的70亿参数新型模型(基础於LLaMA 7B)。具體來說,他們讓OpenAI的text-davinci-003模型以self-instruct方式生成52K条遵循(instruction-following)樣本,用作Alpaca的訓練數據。實驗結果顯示,Alpaca的多種行為與text-davinci-003相似。換句話說,只有一個7B參數的輕量級模型Alpaca的表现能夠匹敵GPT-3.5等超大型語言模型。

对于一般的研究者而言,这种方法是一种实际且经济高效的微调途径。然而,值得关注的是,这种方法仍需消耗相对较大的计算资源(作者透露,他们在8台拥有80GB存储的A100上进行了3小时的微调过程)。此外,Alpaca的种子任务以及所收集的数据均为英语,因此,训练出的模型并未针对中文进行优化。
在探索降低微调成本的可能途径中,一位来自斯坦福大学的研究者——Eric J. Wang,采用LoRa(低秩适应)技术成功复现了Alpaca的成果。具体而言,他仅需利用一台RTX 4090显卡,短短5个小时就能训练出一个与Alpaca水平相当 model,从而将此类模型的计算能力需求降低至消费级水平。更为重要的是,这个模型还可以在树莓派上运行,为研究提供了便捷的硬件环境。

LoRA 的技术原理。LoRA 的思想是在原始 PLM 旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的 intrinsic rank。训练的时候固定 PLM 的参数,只训练降维矩阵 A 与升维矩阵 B。而模型的输入输出维度不变,输出时将 BA 与 PLM 的参数叠加。用随机高斯分布初始化 A,用 0 矩阵初始化 B,保证训练的开始此旁路矩阵依然是 0 矩阵(引自:https://finisky.github.io/lora/)。LoRA 的最大优势是速度更快,使用的内存更少,因此可以在消费级硬件上运行。

Eric J. Wang 发布的 Alpaca-LoRA 项目。
项目地址:https://github.com/tloen/alpaca-lora
对于想要训练自己的类 ChatGPT 模型(包括中文版类 ChatGPT)但又没有顶级算力资源配置的研究者来说,这无疑是一大惊喜。因此,在 Alpaca-LoRA 项目问世后,围绕该项目的教程和训练成果不断涌现,本文将介绍其中的几个。
如何使用 Alpaca-LoRA 微调 LLaMA
在 Alpaca-LoRA 项目中,作者提到,为了廉价高效地进行微调,他们使用了 Hugging Face 的 PEFT。PEFT 是一个库(LoRA 是其支持的技术之一),可以让你使用各种基于 Transformer 的语言模型并使用 LoRA 对其进行微调。好处在于,它允许你在一般的硬件上廉价而有效地微调模型,并有较小的(也许是可组合的)输出。
在近期的一篇博客中,几位研究者介绍了如何使用 Alpaca-LoRA 来微调 LLaMA。
使用 Alpaca-LoRA 之前,需要具备一些先决条件。首先是 GPU 的选择,得益于 LoRA,现在你可以在 NVIDIA T4 这样低规格 GPU 或 4090 消费级 GPU 上完成微调;此外,你还需要申请 LLaMA 权重,因为其权重并不对外公开。
先决条件具备了,接下来就是如何使用 Alpaca-LoRA。首选你需要克隆 Alpaca-LoRA 存储库,代码如下:
git clone https://github.com/daanelson/alpaca-loracd alpaca-lora其次,获取 LLaMA 权重。将下载到的权重值存储到名为 unconverted-weights 文件夹里,文件夹层次结构就像下面这样:
unconverted-weights├── 7B│ ├── checklist.chk│ ├── consolidated.00.pth│ └── params.json├── tokenizer.model└── tokenizer_checklist.chk权重存储好后,接着使用以下命令将 PyTorch checkpoint 的权重转换为 transformer 兼容的格式:
cog run python -m transformers.models.llama.convert_llama_weights_to_hf \ –input_dir unconverted-weights \ –model_size 7B \ –output_dir weights得到最终的目录结构应该是这样的:
weights├── llama-7b└── tokenizermdki处理好上述两步,来到第三步,安装 Cog:
sudo curl -o /usr/local/bin/cog -L “https://github.com/replicate/cog/releases/latest/download/cog_$(uname -s)_$(uname -m)”sudo chmod +x /usr/local/bin/cog第四步来到微调模型,默认情况下,微调脚本上配置的 GPU 功能较弱,但如果你有性能更好的 GPU,则可以在 finetune.py 中将 MICRO_BATCH_SIZE 增加到 32 或 64。此外,如果你有指令调优数据集,则可以在 finetune.py 中编辑 DATA_PATH 以指向自己的数据集。需要注意的是这一项操作应该确保数据格式与 alpaca_data_cleaned.json 相同。接下来运行微调脚本:
cog run python finetune.py微调过程在 40GB A100 GPU 上花费 3.5 小时,对于处理能力较低的 GPU 则需要更多时间。
最后一步用 Cog 运行模型:
$ cog predict -i prompt=”Tell me something about alpacas.”Alpacas are domesticated animals from South America. They are closely related to llamas and guanacos and have a long, dense, woolly fleece that is used to make textiles. They are herd animals and live in small groups in the Andes mountains. They have a wide variety of sounds, including whistles, snorts, and barks. They are intelligent and social animals and can be trained to perform certain tasks.教程作者表示,在完成以上步骤之后,大家可以继续尝试各种玩法,包括但不限于:
带上你自己的数据集,微调你自己的 LoRA,比如微调 LLaMA,让它像动漫角色一样说话。参见:https://replicate.com/blog/fine-tune-llama-to-speak-like-homer-simpson
将模型部署到云平台上;
结合其他 LoRA,比如 Stable Diffusion LoRA,把这些都用到图像领域;
使用 Alpaca 数据集(或其他数据集)微调更大的 LLaMA 模型,并查看它们的表现。这应该可以通过 PEFT 和 LoRA 实现,尽管它需要更大的 GPU。
Alpaca-LoRA 的衍生项目
尽管 Alpaca 性能可以媲美 GPT 3.5,但其种子任务都是英语,收集的数据也都是英文,因此训练出来的模型对中文并不友好。为了提升对话模型在中文上的效果,我们看看都有哪些比较好的项目。
首先是来自华中师范大学、商汤科技等机构开源的中文语言模型骆驼 (Luotuo),该项目基于 LLaMA、Stanford Alpaca、Alpaca LoRA、Japanese-Alpaca-LoRA 等完成,单卡就能完成训练部署。有意思的是,他们之所以将模型名字命名为骆驼,是因为 LLaMA(大羊驼)和 alpaca(羊驼)都属于偶蹄目 – 骆驼科。这样看来,起这个名字也在意料之中。
这个模型是在 Meta 开源的 LLaMA 基础上,参考 Alpaca 和 Alpaca-LoRA 两个项目,对中文进行了训练。
项目地址:https://github.com/LC1332/Chinese-alpaca-lora
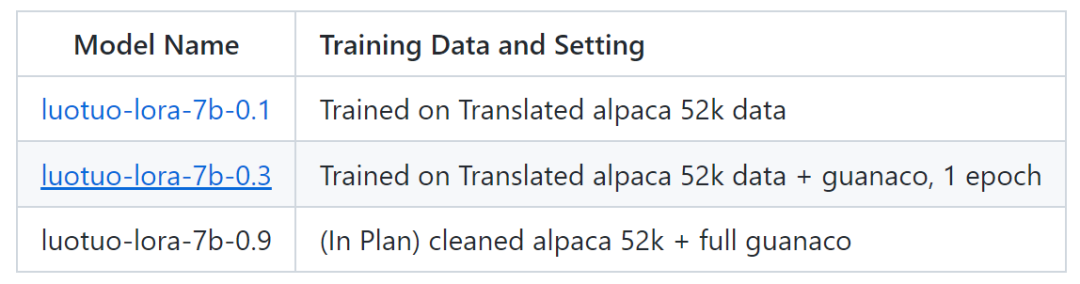
目前该项目释放了两个模型 luotuo-lora-7b-0.1、luotuo-lora-7b-0.3,还有一个模型在计划中:
下面是效果展示:


不过 luotuo-lora-7b-0.1(0.1)、luotuo-lora-7b-0.3(0.3)还是有差距的,在用户询问华中师范大学地址时,0.1 回答错误:

除了进行简单的对话外,还有人在保险相关领域进行了模型优化。据这位推特网友表示,借助 Alpaca-LoRA 项目,他输入了一些中文保险问答数据,最后效果也不错。
具体来说,作者训练中文版 Alpaca LoRa 用了 3K 多条中文问答保险语料,实现过程使用了 LoRa 方法,并微调 Alpaca 7B 模型,耗时 240 分钟,最终 Loss 0.87 。

以下是训练过程和结果:
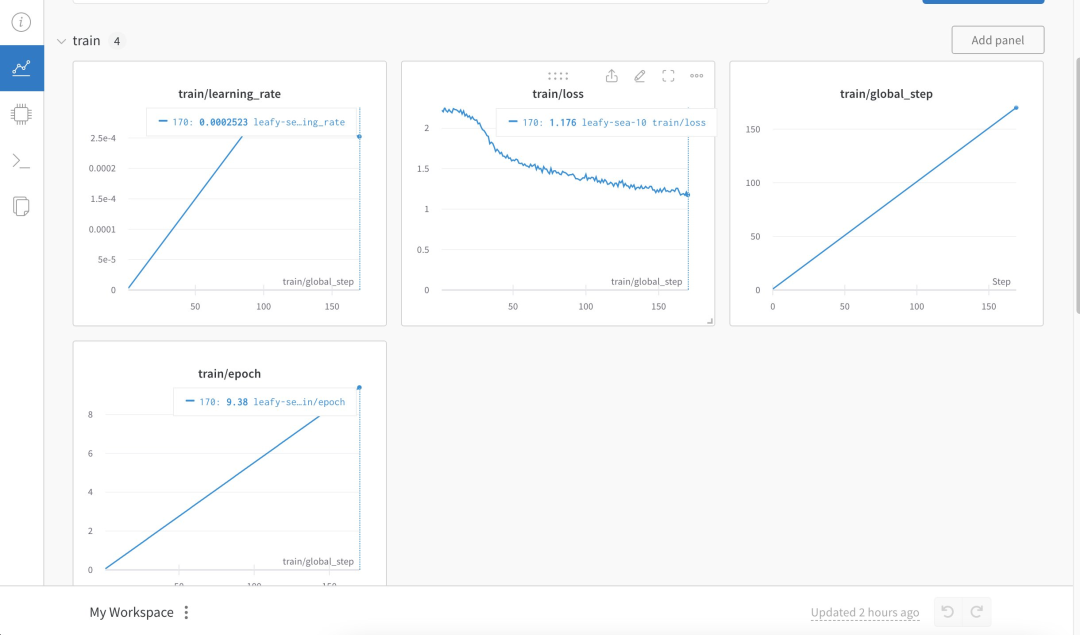
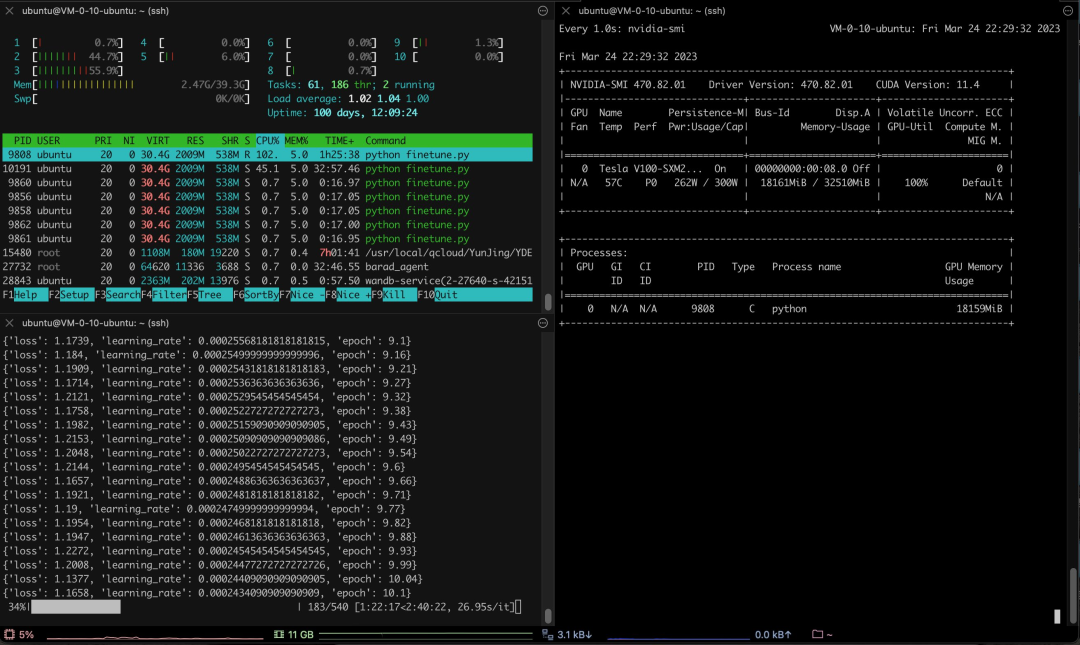
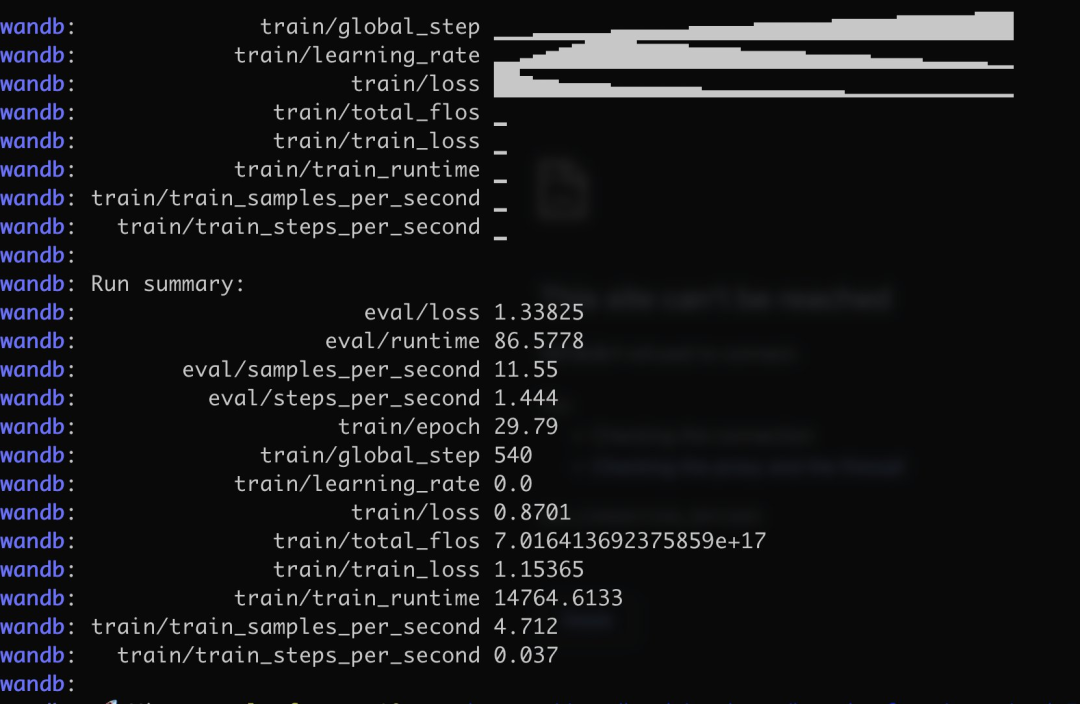
测试结果表明:1. 训练语料相关内容都能有大概合理的回复,但仅限于不胡说 2. 非语料相关内容则会强行回复某个语料内的数据 3. 逻辑推理数学计算则没有这个能力。
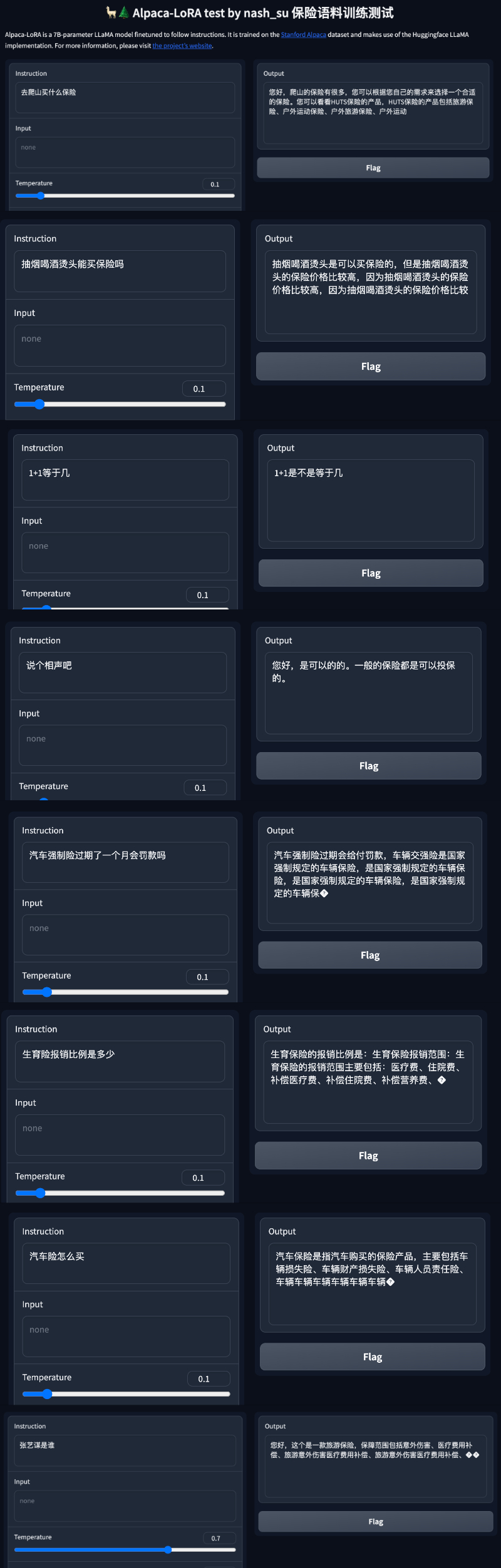
看到这个结果后网友纷纷喊要失业了:

最后期待更多的中文对话模型加入进来。
参考链接:https://replicate.com/blog/fine-tune-alpaca-with-lora?continueFlag=4ecae39885197a5c008faabbefb5c824

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!