理解RLHF中目标函数优化涉及的PPO-
本文主要介绍了在RLHF(Reinforcement Learning with Human feedback)中,目标函数优化所涉及到的PPO-ptx算法的原理。在优化过程中,我们需要考虑人类反馈对模型动作的影响,因此需要引入PPO-ptx算法。本文参考了7月在线的CSDN博客,具体链接为:。
https://blog.csdn.net/v_JULY_v/article/details/128579457, 但是本文将简化相关阐述。1上篇帖子提到RLHF 优化目标函数:2
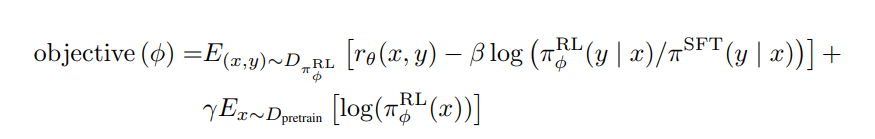
1RLHF优化目标函数2
1其中一共包含三个部分,下面依次进行解析.2
重新组织后的内容:在价值动作函数期望最大化的第一部分中,我们使用了强化学习中PPO算法。PPO算法是OpenAI在2017年提出的一种新型强化学习算法,它可以帮助AI系统更快地学习和改进策略。在这一部分中,我们使用了PPO算法来最大化价值动作函数的期望收益。
第二部分是一个KL 散度,期望学习到的最终模型参数和初始的SFT模型参数不要偏离太大,注意,这个KL散度和下文要讲的PPO已经没有关系了,只是一个KL散度约束的普通应用.
1第三部分2
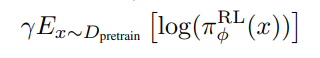
1和预训练模型输出结果不要差太大2
1这部分要求模型在RLHF 调优过程中,不至于和初始模型变化太大,太过拟合人类偏好.2
1总体对损失函数进行变换推导,实际工程实现是基于如下式子进行优化:2
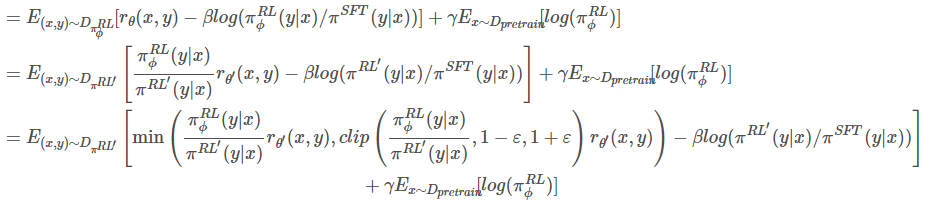
1PPO-ptx 算法2
1这里简要介绍一下 PPO 算法的思想,直接学习策略价值函数较难的情况下,强化学习在采样下对优势函数进行优化.2
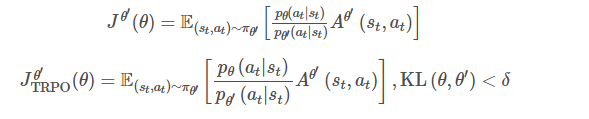
1TRPO 算法2
1带条件的约束最优化,依据拉格朗日乘数算法可以转换为如下式子:2
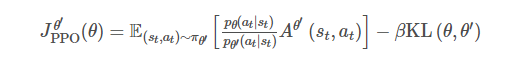
1PPO 优化算法2
1在机器学习中,KL散度是一种常用的度量函数,用于衡量两个模型之间的相似度。然而,在计算KL散度时,需要对模型的输入进行采样,这可能会导致模型和真实世界之间的偏差。为了约束这种偏差,引入了KL散度约束,它通过限制模型的输出和真实值之间的KL散度来保证模型的输出与真实值之间的相似度。2KL散度约束是一种常用的机器学习约束方法,可以用于约束模型的输出和真实值之间的相似度。在计算KL散度时,需要对模型的输入进行采样,这可能会导致模型和真实世界之间的偏差。为了约束这种偏差,引入了KL散度约束,它通过限制模型的输出和真实值之间的KL散度来保证模型的输出与真实值之间的相似度。这种约束方法可以用于约束多种模型之间的关系,并可以用于解决许多机器学习问题。
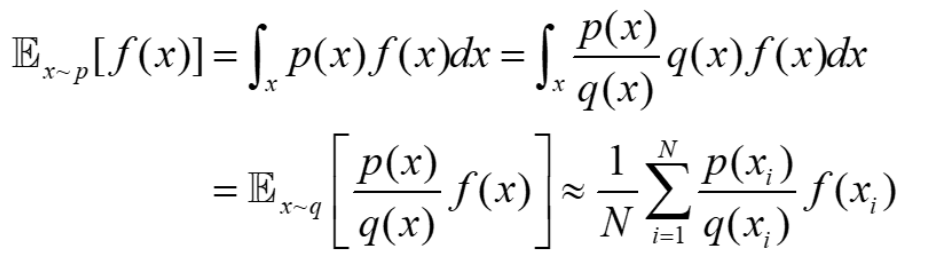
1从q 中采样,代入后面的求和函数列中,计算f(x) 的期望2
1这里尽管这样做期望相等,但是方差是存在偏差的,具体推到如下:2
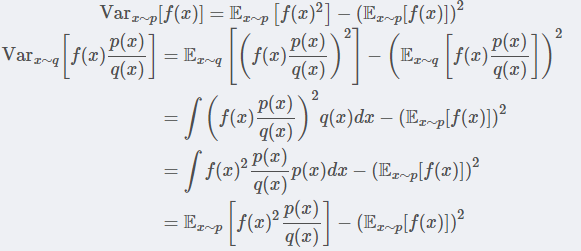
1重要性采样方差计算2
第一项多了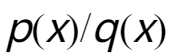 ,只有两者相等的时候,才能保证两者的方差相等,因此实际数据优化过程中使用KL散度来限制来解决这个问题。
,只有两者相等的时候,才能保证两者的方差相等,因此实际数据优化过程中使用KL散度来限制来解决这个问题。