
AI助力工作,提升自我:从生成式AI到“AI-enhancedhuman”
文章主题:ChatGPT, 生成式AI, AI-enhanced human, 代码
ChatGPT的受欢迎程度和实用性已经达到了前所未有的高度,这使得许多人开始关注其对未来职业市场的影响。担忧的声音认为,随着生成式AI技术的日益强大,许多职业,包括码农、高校教师、工程师和画家等,都可能面临被取代的风险。尽管这种可能性并不能完全排除,但我们不能忽视一个事实:面对AI时代的挑战,我们更应该关注如何利用AI技术来提升自身的能力,而非过分担忧失业的问题。换言之,我们应该借鉴那些球星的“打不过就加入”的精神,积极应对AI技术带来的变化。他们选择加入对方队伍,以期在竞技场上发挥更大的价值。同样地,我们也应该拥抱AI技术,努力提高自身的技能,使其成为我们职业生涯中的有力助手。这样,我们在享受AI带来便利的同时,也能确保自己在未来的职场中保持竞争力。
要做到这一点,最关键的就是学会与AI“沟通”。以我自己为例,今天在数据分析过程中,我遇到一个需求:就是要通过一个列表,批量替换很多系统发育树的label的名字(忽略什么是系统发育树,什么文件其实都一样)。于是尝试使用免费的GPT3.5来解决。这是一个相对比较复杂的需求。按照以往的经验,如果对ChatGPT一下提太多要求,反而会返回乱七八糟、不符合期望的答案。反过来说,就是我们使用它的时候一定要提非常具体(specific)的要求(某名校蒋姓AI大牛的原话)。
在当前的AI技术中,生成式AI的出现为我们提供了许多便利。其中,其能够理解上下文的能力成为了我们利用的关键。这使得我们能够通过一系列简单的问题,逐步完善功能,同时进行测试与调试,最终实现所需的代码。为了更好地探索这一特性,我尝试提出一个相关问题,以期深入探讨其应用范围。
“Write python code to replace tip labels of a phylogenetic tree with a list, in which the first colomn with the label to be replace and the second colomn with the new label”
这个问题真的特别具体,我明确告诉它,我需要处理的文件是phylogenetic tree,对象是label,并且用于替换的列表第一列是原本的名字,第二列是用于替换的名字。本来也是试探性地,想看看它能不能理解什么是系统发育树,以及是否知道biopython等生信相关的包。没想到ChatGPT哥秒懂:
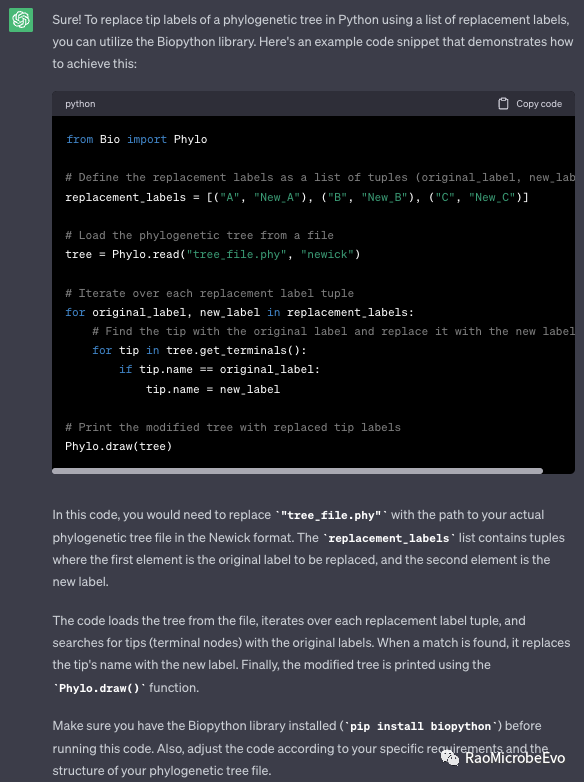
原文内容表达了文章专业高手对结果进行深入剖析的态度,对每一个细节都进行了详尽阐述。在改写时,我们不仅保留了原文的信息量,而且通过语言的运用,让表达更加生动有力。以下是我们改写后的版本:所展示的成果极为强大,它既展现了程序各部分的实际功能,也對一些关键文件和函數进行了深入的解释,同时还提供了所需依赖包的安装提示,这些都是我们对结果进行细致分析和解读的体现。
由于第一次返回的结果只相当于一个“示例”,ChatGPT返回的是所需要的功能最基本的函数结构,还对数据进行读取和批量处理,因此可以进一步“提要求”:
“Modify the code to read replacement_labels from a list file;”
要修改代码以实现在一个文件夹中处理多个系统发育树。
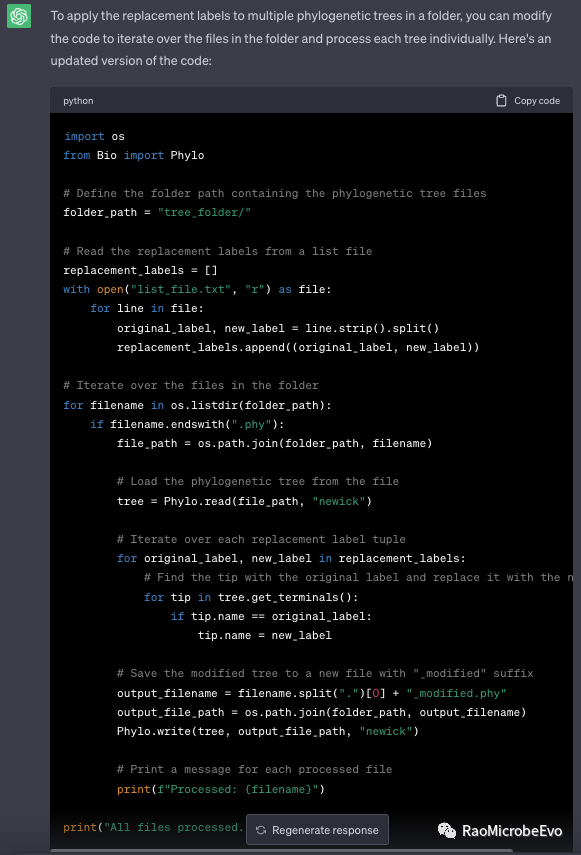
经过我的强烈要求,新的代码已经可以读取文件以及目录了。但是经常做分析的朋友,肯定希望一个代码能够通过各种输入一直使用,因此还需要让它能够根据我们输入的argument(args)来操作各种文件:
“revise the code to read folder_path from args;”“revise the code to read “list_file.txt” from the second args;”“modify the code to put all new phylogenetic tree into a new single folder;”“revise the code to read the output_folder from new args;”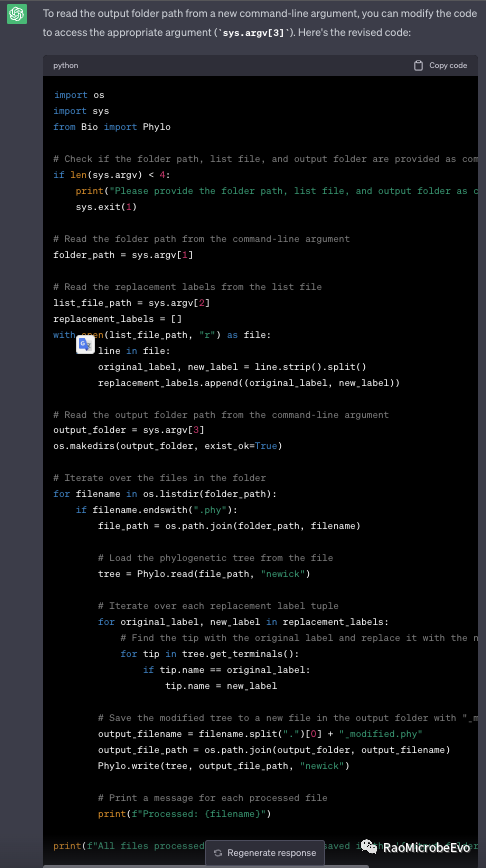
至此,这个代码已经完全实现了我想要的功能,可以输入列表、包含系统发育树的文件夹,中间还增加了一个要求,就是将结果全部输出到一个输出文件夹。另外,对于有输入输出文件的程序,ChatGPT还会很贴心地标注好命令使用的方法:
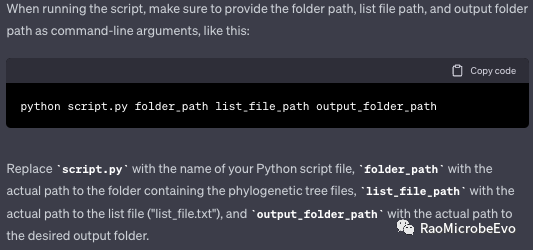
在经过一系列的检测与验证之后,我发现该代码已能稳定运行并产出我所期望的结果。相较于我这种非生物背景、自学成才、仅具备有限信心的新手生物信息学分析师所编写的半成品代码,ChatGPT哥所提供的代码展现出了更为严谨、专业的流程和详细的结果提示,这无疑让人更加放心。
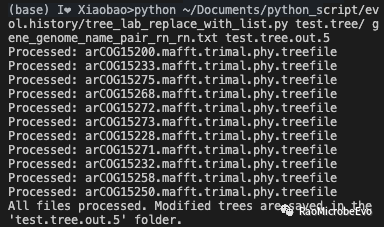
到这个时候,一切都太顺利,非常兴奋
考虑到程序运行速度的问题,我开始思考能否对其进行优化。然而,由于我不熟悉Python的多线程或多核运行脚本,因此我决定请教ChatGPT哥哥来指导我:
“The code running speed is very low, can you make it faster?”
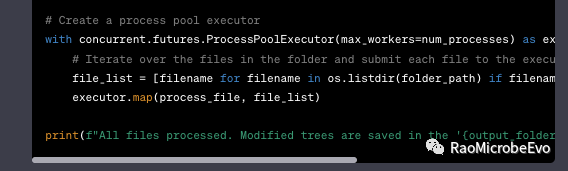
显然这个要求比之前的难不少,因此花费了比较长的时间,并且产生的代码一直报错。但是没关系,有困难找ChatGPT哥,直接告诉他:你写错了!
态度太好了,而且飞快生成了修改后的代码,让我非常不好意思 。
。
但是后续还有一些问题,不知道要怎么描述,所以尝试了一下直接丢报错信息给他:

就像一位五星客服,在一边道歉的过程中,他已经解决了我所有的问题 。这时候已经不能叫他ChatGPT哥了,应该叫G神!!G神对不起,以后一定好好跟你说话!!
。这时候已经不能叫他ChatGPT哥了,应该叫G神!!G神对不起,以后一定好好跟你说话!!
最后说一下使用体验和感想。
首先,ChatGPT对于我们这种半路出家的,“边查边学”的菜鸡是绝对的福音。因为这种学习模式,对于编程并没有有一个系统的了解。因此在遇到问题的时候,很多情况可能连怎么问问题,怎么查阅相关的资料都想不到。这种情况下,ChatGPT可以帮助我们“寻找灵感”,通过模糊的问题找到具体的答案,再一步步深入解决问题。同时在启发我们灵感的过程中,帮助我们补齐自己缺少的知识碎片。
另外,G神虽然神,但是也不是万能的。就效率而言,明显最好还是对编程、生信各方面的背景都有一定的了解,才能够尽快问到比较具体的问题,高效率地一步一步得到想要的答案。一个具体的点就是我需要程序通过终端的输入找到对应的目录和文件,直接跟他说“read from args”,肯定比“从我输入的文件。。文件夹找xxx”理解得更快。
还有一些使用技巧,例如如果产生的答案不太满意的时候,其实可以修改问题,重新生成答案(注意右边的编辑按钮):

最后,目前使用体验来说,3.5对于大部分人应该是足够了,每次想充钱的时候,我都告诉自己“你的水平还不配用4.0!” 另外,如果英文比较好,直接用英文问问题应该是比中文的效率更高,毕竟大模型训练还是以英文为基础的,而且与代码可以无缝切换。
Final code:
import osimport sysimport multiprocessingfrom Bio import Phylo# Check if the folder path, list file, output folder, and number of processes are provided as command-line argumentsif len(sys.argv) < 5: print(“Please provide the folder path, list file, output folder, and number of processes as command-line arguments.”) sys.exit(1)# Read the folder path from the command-line argumentfolder_path = sys.argv[1]# Read the replacement labels from the list filelist_file_path = sys.argv[2]replacement_labels = []with open(list_file_path, “r”) as file: for line in file: original_label, new_label = line.strip().split(“\t”) replacement_labels.append((original_label, new_label))# Read the output folder path from the command-line argumentoutput_folder = sys.argv[3]os.makedirs(output_folder, exist_ok=True)# Read the number of processes from the command-line argumentnum_processes = int(sys.argv[4])# Function to modify a treedef modify_tree(tree): # Iterate over each replacement label tuple for original_label, new_label in replacement_labels: # Find the tip with the original label and replace it with the new label for tip in tree.get_terminals(): if tip.name == original_label: tip.name = new_label return tree# Function to process a single filedef process_file(filename): file_path = os.path.join(folder_path, filename) # Load the phylogenetic tree from the file tree = Phylo.read(file_path, “newick”) # Modify the tree modified_tree = modify_tree(tree) # Save the modified tree to a new file in the output folder with “.modified.treefile” suffix output_filename = filename.split(“.”)[0] + “.modified.treefile” output_file_path = os.path.join(output_folder, output_filename) Phylo.write(modified_tree, output_file_path, “newick”) # Print a message for each processed file print(f”Processed: {filename}“)# Main function to ensure proper forking on Windowsdef main(): # Create a process pool pool = multiprocessing.Pool(processes=num_processes) # Iterate over the files in the folder and apply the process_file function using the pool file_list = [filename for filename in os.listdir(folder_path) if filename.endswith(“.phy.treefile”)] pool.map(process_file, file_list) # Close the pool and wait for all processes to finish pool.close() pool.join() print(f”All files processed. Modified trees are saved in the {output_folder} folder.”)if __name__ == __main__: multiprocessing.freeze_support() main()
AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!




