《大模型时代:不同格式间的转换与协作》
文章标签:当下大模型的在各行各业的落地, 不同形式数据之间的转换, Control Anything, 集成调用不同服务之间进行合作

当下大模型的在各行各业的落地,已经开始展开,也有很多的文章展开论述。
然而,在当前如何更好地自主地大一统地解决复杂场景,一直是人工智能技术发展应用落地的一个大的方向。
本文也将谈谈从技术实现角度上看,当下大模型的三种落地场景范式。
老刘通过对现有开源的项目实现,大致将大模型的落地归为Trans Anything、Ask Anything、Control Anything三种类型。
其中:
Trans Anything,指的是
在数字化的世界里,各种形式的數據交换和轉換扮演著重要的角色。從代碼(Code)、文本(Text)、圖像(Image)到視頻(Video),這些不同的數據格式都有其獨特的特點和用途。對於大模型來說,能夠實現這些不同形式數據之間的轉換和互操作,不僅是可能的,而且對模型的發展和應用都具有重要意義。
Ask Anything,指的是作为一种以QA形式进行交互的新模式,极大的冲击了问答场景。从一般的闲聊,到面向特定文档的问答,到面向各种复杂文档、知识库、多模态等场景,均可以通过构造问题,来获得问题对应的答案。
“Control Anything”是一种策略,其目的是实现不同模型和服务之间的协同决策,以达到各模型间的高效合作。这是智能体的 optimal 表现,它通过整合和调度各个服务之间的协作,整合各模型的能力,以达成更为宏大的目标。该策略的主要实施方式是采用 GPT-4、Pinecone 和 LangChain 等多模型的组合,以支持多元化的应用场景,并实现任务驱动的自主代理。
这三种范式是属于递进的关系,Transfer Anything可以为Ask Anayting提供基础数据,Ask Anything可以以QA形式完成多种应用生产,并提供服务,Control Anayting则作为上层可以调度两者,以集成更多、更全面的力量,来实现更大的收益。
一、Generative AI Market基本情况
以 article 形式表达:LEONIS CAPITA 机构针对当前生成领域的最新情况,构建了 Generative AI Market Map,并聚焦于现有的关键制造商,包括他们在 RESEARCH、TEXT、IMAGE、VIDEO、AUDIO、CODE、GAMING 和 BIOTECH 等类别上的集中表现。
从中我们可以看到国外市场的布局。
1、RESEARCH

2、TEXT

3、IMAGE

4、VIDEO
5、AUDIO
6、CODE
7、GAMING
8、BIOTECH

三、Trans Anything范式
我们发现,我们所有的应用生产,都是在面对不同的数据,作不同的处理,完成包括信息过滤、信息加工,以产出不同的数据价值。
但在实际的业务落地中,我们发现,不同的数据,在传统的落地中都是需要依靠不同的技术栈、技术模型来做不同的处理,这显然十分费力。
大模型如ChatGPT的出现,为真正的大一统提供了可能性,这无疑是人工智能领域的一大突破。更为重要的是,这些大模型能够实现各种模态和格式的转换,从而实现现有模型的统一交互,这在很大程度上推动了人工智能技术的进步。
我们定义为,Trans anything表示不同形式数据之间的转换,包括代码code、文本text、图像image、视频video等不同形式之间的互转,这些场景在大模型都有机会实现。
例如:
1、code2code:不同代码种类之间的转换,如python转c,c转python等,这可以加速代码开发效率;


2、code2text:代码转换为文本,应用场景为代码审查、代码分析;

3、text2text:文生文,应用场景为文本摘要、视频会议纪要等;
Input: TypeScript是一种静态类型的编程语言,它提供了许多现代编程语言中的功能,如类、接口、模块等。TypeScript还可以编译成JavaScript代码,使得开发人员可以在现有的JavaScript代码库中使用TypeScript,并且不会影响原有代码的运行。TypeScript的设计目标是提供一种能够提高开发人员编写可靠、可维护代码的语言。通过引入类型系统,TypeScript可以帮助开发人员更好地理解代码的结构和行为,减少在运行时出现错误的可能性。此外,TypeScript还提供了其他一些功能,如命名空间、接口、模块等,这些功能可以帮助开发人员更好地组织和管理代码。TypeScript是一种强大的工具,可以帮助开发人员编写更加可靠、可维护的代码。如果你正在开发一个大型项目,或者你希望提高自己在编程方面的技能,那么学习TypeScript是一个不错的选择。
这件文艺个性的印花连衣裙以其独特的风格吸引了我的注意。其藏青色的底蕴,低调中透露出的大气,令人印象深刻。整件裙子上的撞色太阳花图案,既绚丽又美好,充满了时尚感和减龄气质。基础款的舒适圆领,简约而不失大方,能够完美地勾勒出精致的脸庞。领后的包布扣设计,使得穿脱变得十分方便。前片立体的打褶设计和后片压褶的製作,不仅增添了层次感,更使得身材显瘦而有型。总的来说,这件连衣裙的设计既具有艺术性,又不失实用性,无论是搭配什么样的服饰,都能展现出独特的美感。
4、text2code:文本转代码,应用场景为自动代码生成、低代码平台开发,自然语言转sql等,提升代码效率;
text2image是一种将文本信息转化为图像的技术,它可以根据输入的文本内容生成相应的图片。这种技术的应用场景非常广泛,包括广告配图、业务配图等等。通过使用text2image技术,我们可以在不需要手动绘制图像的情况下,快速生成高质量的图片,从而节省时间和精力。

例如项目:
在GitHub上有一个名为“PaddlePaddle/PaddleNLP”的仓库,其中包含了一个名为“text_to_image”的示例 pipeline。这个pipeline主要用于将文本转换为图像。具体而言,它会利用PaddlePaddle深度学习框架中的NLP技术,将输入的文本转化为图像。该pipeline的实现细节可以在其GitHub页面中找到。
6、image2text:图生文,根据图像生成文本,应用场景为自动报道生成,图像解读。
来自于:https://www.microsoft.com/en-us/research/project/image2text-2的例子
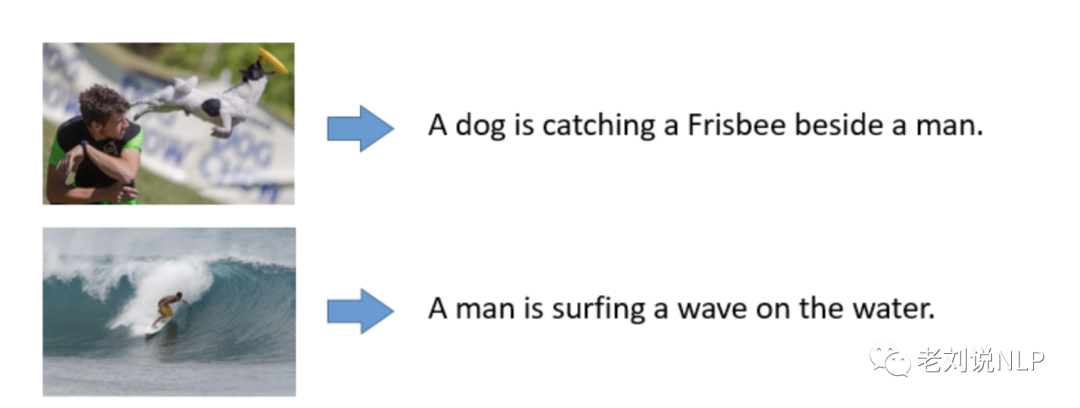
7、text2video:文本生成视频,尤其是在具有时序性的文本,生成为视频,应用场景为游戏、漫画生成;
来自:https://huggingface.co/damo-vilab/text-to-video-ms-1.7b-legacy的例子
An astronaut riding a horse.

Darth vader surfing in waves.

8、video2text:视频生成文本,应用场景为视频总结、视频分析;
二、ASK Anything落地范式
类Chatgpt大模型出现后,作为一种以QA形式进行交互的新模式,极大的冲击了问答场景。从一般的闲聊,到面向特定文档的问答,到面向各种复杂文档、知识库、多模态等场景,均可以通过构造问题,来获得问题对应的答案。
1、处理各种不同格式文档的代表项目
在此推荐一个可以处理多种复杂格式文档的开源项目:textract
地址:https://textract.readthedocs.io/en/stable/
使用项目:
textract path/to/file.extensiontextract支持越来越多的文件类型列表用于文本提取,其中集成实现了如下格式文档:
.csv通过python内置; .doc通过反词; .docx通过python-docx2txt; .eml通过python内置; .epub通过ebooklib; .gif通过 tesseract-ocr; .jpg和.jpeg通过tesseract-ocr; .json通过python内置; .html和.htm通过beautifulsoup4; .mp3通过 sox、SpeechRecognition 和 pocketsphinx; .msg通过msg-extractor; .odt通过python内置; .ogg通过 sox、SpeechRecognition 和 pocketsphinx; .pdf通过pdftotext(默认)或pdfminer.six; .png通过 tesseract-ocr; .pptx通过python-pptx; .ps通过ps2text; .rtf通过unrtf; .tiff和.tif通过tesseract-ocr; .txt通过python内置; .wav通过SpeechRecognition和pocketphinx; .xlsx通过xlrd; .xls通过xlrd;2、ask video
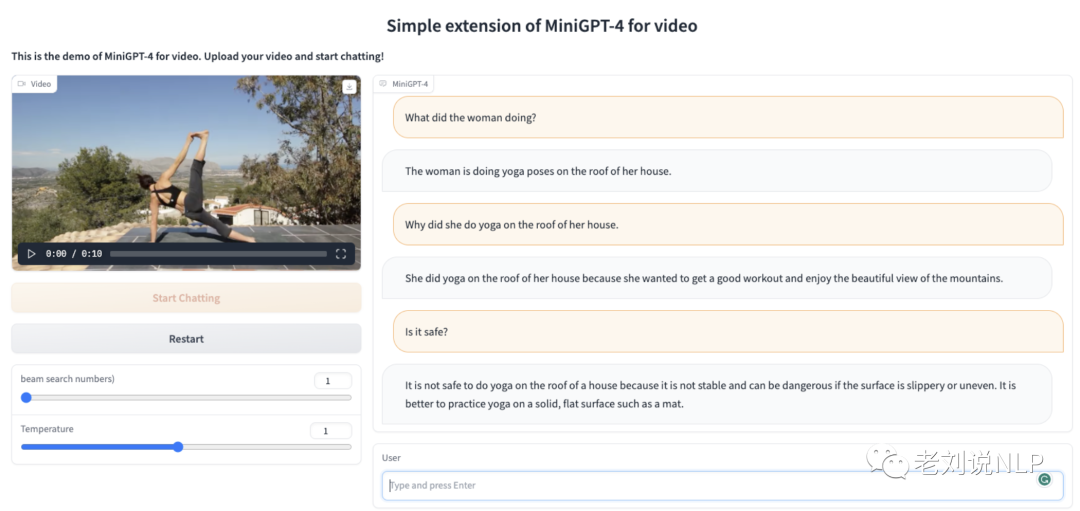
Ask-Anything是一个简单而有趣的与视频聊天工具,该团队正在努力建立一个智能且强大的用于视频理解的聊天机器人。
项目地址:https://github.com/OpenGVLab/Ask-Anything/blob/main/README_cn.md
实现思路也很简单,以minigpt4为例:
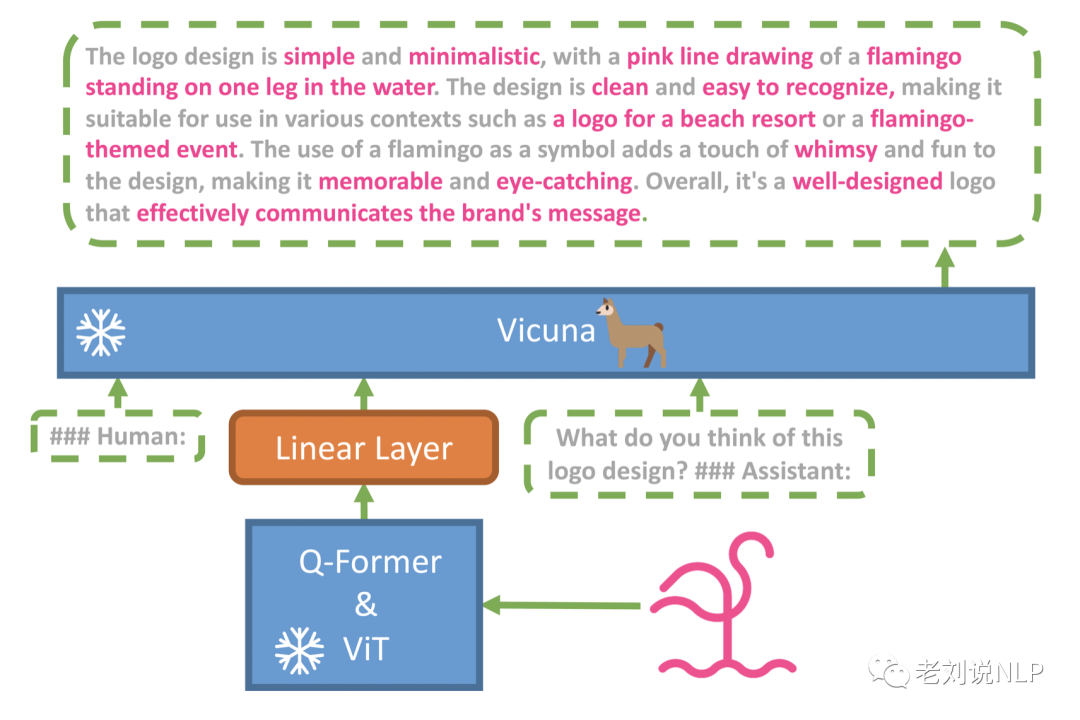
依赖于两个基础模型,分别对应于文本模型和视觉模型,在该模型中,文本模型使用Vicuna,视觉模型使用BLIP-2,总体将BLIP-2的冷冻视觉编码器与冷冻LLM Vicuna对齐,只使用一个投影层,以解决从视觉到文本的转换。
2、ask documents
以chatpdf、langchain为代表的项目,通过对文档进行封闭性的问答,其实现思路很简单,大致如下:
1)Azure的解决方案
 fill=%23FFFFFF%3E%3Crect x=249 y=126 width=1 height=1%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
1)文章切片到段落;
2)通过 OpenAI 的 embedding 接口将每个段落转换为 embedding;
3)将提问的问题转换为 embedding
4)把问题的 embedding 比较所有段落 embedding 得到近似程度并排序 ;
5)把和提问(语义)最接近的一个或几个段落作为上下文,通过 OpenAI 的对话接口得到最终的答案
2)单文档解决方案
四、Control Anything范式
Control Anything,指的是对不同模型、不同服务之间的决策,以实现不同模型之间的有效协作,这个也是智能体的一个最佳表现,通过集成、调动不同服务之间进行合作,集成不同模型的能力,以完成一个更大的目标。
其主要实现形式为利用GPT-4、Pinecone和LangChain进行多种应用,实现任务驱动的自主代理。以AutoGPT为例,(自动)工作原理如下:提出问题,即设定一个目标->AutoGPT 根据设定的目标,拆解主任务-> 分别并执行各个主任务,然后得到结果-> 当主任务执行完成后,会执行额外的添加的子任务。
1、AutoGPT
项目地址:https://github.com/Significant-Gravitas/Auto-GPT
其核心在于它把我们的命令发送给GPT-4的时候,让GPT-4根据指定的COMMAND来选择操作,上述COMMAND中,大家可以看到包括谷歌搜索、浏览网站、读写文件、执行代码等。AutoGPT会把问题,如“寻找今天推特上最火的AI推文”发给GPT-4,并要求GPT-4根据这些COMMAND选择最合适的方式去得到答案,并给出每一个COMMAND背后需要使用的参数,包括URL、执行的代码等。
2、HuggingGPT
解决不同领域和模式的复杂人工智能任务是迈向高级人工智能的关键一步。虽然有丰富的人工智能模型可用于不同的领域和模式,但它们不能处理复杂的人工智能任务。
考虑到大型语言模型(LLMs)在语言理解、生成、交互和推理方面表现出的卓越能力,我们主张LLMs可以作为一个控制器来管理现有的人工智能模型,以解决复杂的人工智能任务,而语言可以作为一个通用接口来授权。
地址:https://github.com/microsoft/JARVIS
基于这一理念,HuggingGPT,利用LLM(如ChatGPT)来连接机器学习社区(如Hugging Face)中各种人工智能模型的框架,以解决人工智能任务。具体来说,使用ChatGPT在收到用户请求时进行任务规划,根据Hugging Face中的功能描述选择模型,用所选的AI模型执行每个子任务,并对响应情况进行总结。
HuggingGPT的整个过程可以分为四个阶段:
3、BabyBeeAGI
BabyBeeAGI,用GPT-4改进的BabyBeeAGI扩展了BabyAGI代码,提高了任务管理、依赖任务、工具、适应性和集成能力。该代码适合处理更多更复杂的任务,但需要更高的计算能力。
地址:https://github.com/yoheinakajima/babyagi
该脚本通过运行一个无限循环来完成以下步骤:
从任务列表中抽出第一个任务->将任务发送给执行代理,执行代理使用OpenAI的API来完成基于上下文的任务->丰富结果并将其存储在Chroma/Weaviate中->创建新的任务,并根据目标和前一个任务的结果重新确定任务列表的优先次序。
我们可以看下该图中的细节:
execution_agent()函数是使用OpenAI API的地方。它需要两个参数:目标和任务。然后它向OpenAI的API发送一个提示,并返回任务的结果。该提示由人工智能系统的任务描述、目标和任务本身组成。然后,结果以字符串形式返回。
task_creation_agent()函数是OpenAI的API用来根据目标和前一个任务的结果来创建新的任务。该函数需要四个参数:目标、前一个任务的结果、任务描述和当前任务列表。然后,它向OpenAI的API发送提示,API以字符串形式返回新任务的列表。然后,该函数将新任务以字典列表的形式返回,其中每个字典包含任务的名称。
prioritization_agent()函数是使用OpenAI的API来重新确定任务列表的优先级的地方。该函数接受一个参数,即当前任务的ID。它向OpenAI的API发送一个提示,后者将重新优先排序的任务列表作为一个编号的列表返回。
最后,该脚本使用Chroma/Weaviate来存储和检索任务结果的背景。脚本根据TABLE_NAME变量中指定的表名创建一个Chroma/Weaviate集合。然后使用Chroma/Weaviate将任务的结果与任务名称和任何额外的元数据一起存储在集合中。
参考文献
1、https://yoheinakajima.com/task-driven-autonomous-agent-utilizing-gpt-4-pinecone-and-langchain-for-diverse-applications/
2、https://www.microsoft.com/en-us/research/project/image2text-2/
总结
本文主要通过对现有开源的项目实现,大致将大模型的落地归为Trans Anything、Ask Anything、Control Anything三种类型。
其中,这三种范式是属于递进的关系,Trans Anything可以为Ask Anayting提供基础数据,Ask Anything可以以QA形式完成多种应用生产,并提供服务,Control Anayting则作为上层可以调度两者,以集成更多、更全面的力量,来实现更大的收益。
实际上,在当前,如何更好地自主地大一统的解决复杂的场景,一直是人工智能技术发展的一个大的方向,Trans 和ASK可以解决大一统的问题,Control可以解决自主和复杂的问题,这些都是未来的发展方向,我们可以跟随住这个潮流。
进技术交流群请添加AINLP小助手微信(id: ainlp2)
请备注具体方向+所用到的相关技术点
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP小助手微信(id:ainlp2),备注工作/研究方向+加群目的。
阅读至此了,分享、点赞、在看三选一吧?
当下大模型的在各行各业的落地, 不同形式数据之间的转换, Control Anything, 集成调用不同服务之间进行合作