ChatGPT的出现:对NLP领域的冲击与启示
文章标签:年末, AIGC, ChatGPT, 自然语言处理
时至年末,恰逢最近圈内新闻(AIGC, ChatGPT)和想法都比较多,在此小结一下。
关于科研
工作方式的转变
在今年,我们实验室成立了一个基础模型小组。与以往那种“想到哪里做到哪里”的工作模式相比,我们现在更加注重从长远的角度来规划和思考。这些理念其实在前面的回答中我们已经提出过了,比如关注基础研究的重要性,以及如何在实际工作中贯彻这一理念等。
作为一名具有严谨要求的 article writing expert,我非常注重细节和深度。针对您提供的主题,我将为您提供一篇更具深度和专业的文章,同时保持字数不少于原文。在开始写作之前,我想先强调一点:对于一个有追求的创作者来说,选择正确的方向是非常重要的。方向错了,无论你多么努力地付出,也很难取得理想的结果。因此,在做出任何决定之前,我们需要深入思考并审慎评估。在我个人的经验中,我发现一个有效的判断方法是“跟随直觉”。我们的直觉往往是由我们的内心深处所驱动,它能够告诉我们哪些事情是真正重要的,哪些事情是可以忽略的。然而,这并不意味着我们要完全依赖直觉。相反,我们需要通过深入的思考和研究来验证我们的直觉,以确保我们选择的方向是正确的。具体来说,我会采用以下几个步骤来确定正确的方向:首先,我会对自己的兴趣和热情进行反思。我需要找到那些让我感到兴奋和充满热情的主题,因为这些主题才是我真正的动力所在。其次,我会考虑自己的能力和资源。我需要确保我选择的方向是我可以胜任的,并且我有足够的资源和能力来实现它。最后,我会参考他人的经验和意见。与更有经验的同事或导师交流,听取他们的建议和反馈,可以帮助我更客观地看待自己的情况,从而做出更好的决策。总的来说,选择正确的方向并不是一件简单的事情,需要我们经过深思熟虑和严谨的评估。在我个人的实践中,遵循上述原则已经帮助我成功地避免了多次错误的方向选择,从而更好地实现了自己的创作目标。
今年(主要是上半年)我们在里面的几个方向完成了几个工作:Black-Box Tuning (ICML), BBTv2 (EMNLP), Late Prompt Tuning (EMNLP findings), Metric Fairness (EMNLP), DiffusionBERT (arxiv),还有稍早一点的ElasticBERT&ELUE (NAACL), HashEE (ACL findings), Paradigm Shift Survey (MIR). 下半年我们参与组织了一个语言模型无梯度调优竞赛,加上各种杂事和塞尔达,生产力大幅降低,深感multitasking能力受到了挑战。
在今日的视角下,这些工作的表现尚待提升。这主要源于两点原因:其一,要在自己所认可的领域中系统性地推进一系列工作,实际上是一项极具挑战性的任务;其二,自2019年BERT问世以来,NLP领域相对较为平静(可以追溯到2019年的BERT时代),缺乏令人振奋的新突破。然而,如今这一切都已不再重要,因为ChatGPT的出现将带来全新的变革。
永远会有好东西出来
在2022年初,当我回顾了近年来自然语言处理(NLP)的发展轨迹(详见上文的幻灯片)后,我的心情有些失落。主要原因是,大部分具有重大影响力的研究成果都是在Word2Vec/LSTM4NLP/Transformer/BERT等先进技术出现后的初期完成的。留给后来者更多的是对现有技术的改进和完善,虽然也有一些改进得相当出色的,但仅仅拥有技术手段并不能产生深远的影响。结合已知的发展路径(具体内容可参见之前的幻灯片),当时的我确实难以预见到未来还有哪些发展可能性。
把越来越多的模块放到预训练里来:embedding (word2vec) –> encoder AND/OR decoder (BERT, GPT, etc.) –> MLM/NSP head (prompt) –> data form (instruction tuning),已经基本见顶;把强大的预训练模型用在机器学习流程中的其他部分:数据 (retrieval), 优化 (learn to optimize), 指标 (BERTScore, MoverScore, etc.),各个赛道也已经挤满人了。在我之前的回答中,我也曾提及过,关于NLP领域,下一个BERT的出现路径可能在何处展现其独特作用。是否会在GLUE/SuperGLUE等领域取得重大突破,使得问题变得失去挑战性?然而,我认为当前的深度学习范式尚无法实现这一目标。因此,在那时,感觉能够实现的优秀想法确实所剩无几。尽管如此,天空仍然飘着几朵乌云,如in-context learning、chain-of-thought以及模块化等方向,这些问题暂时按下不提。
NLP领域的独特魅力在于其不断涌现出令人惊喜的成果。当人们认为现有的技术已经到达了极限时,总会有人创造出新的、革命性的技术来改变一切。近年来,许多卓越的研究成果(如Word2Vec、ELMo、Transformer、BERT、GPT和ChatGPT)几乎未涉及到任何远离NLP领域的工具,而只是通过巧妙地组合和扩展现有的技术来实现。
在2022年的岁末,ChatGPT的问世无疑给人工智能领域带来了翻天覆地的变化。它不仅为我们提供了新的答案,而且将过去的发展逻辑置于一个更广阔的背景之中。这标志着以第一人称为主导的交互式AI已经成为了必然的发展趋势。值得注意的是,下一个BERT并不是一个只會刷分的考生,反而以人为评估标准,这一改变无疑更加准确地反映了人类的智能水平。经过多年的发展,AI已经站在了人类这个最终的考官面前,如何更好地与人类配合成为了新的具有高影响力的研究方向。然而,令人尴尬的是,在我们拥有强大的基础模型之前,我们仍然无法深入研究这个问题。
语言模型即服务与黑箱优化
在 ChatGPT 的出现之后,相信许多人都在重新审视自己过去的工作意义。尽管在 2022 年仍有一些领域,如使用 LSTM Attention 的领域,不需要过多的思考,但 ChatGPT 在大部分常见的 NLP 任务上,其表现明显优于过去的工作。那么,语言模型即服务 (LMaaS) 和黑箱优化 (Black-Box Tuning) 又会怎样呢?我认为它们前景十分广阔。
LMaaS的假设是我们只能获取大模型的API而无法获取其参数和梯度,因此我对LMaaS最焦虑的时候是BLOOM和OPT出现的时候,研究社区对于开源模型的追求令人感动。可惜魔高一丈,OpenAI不open。Percy Liang的HELM已经表明不开源的模型通常远远强于开源的模型,新出的ChatGPT又是一个只有API的模型,甚至这次连paper都不给看了。可以预计的是,随着大模型预训练和部署成本的急剧增大,未来好用的基础大模型可能都会采取这种方式,而这种方式就是LMaaS。
最近Sam Altman (OpenAI CEO)也提到,未来在少数几个底层基础模型和上层应用之间应当还会出现一个中间层,基于底层模型的服务适配特定的上层应用,这就是LMaaS和黑箱优化要做的事。
关于ChatGPT
铺垫了这么久,终于可以聊一聊ChatGPT了。最近线上线下有非常密集的关于ChatGPT的讨论,关于其中用到的具体技术有很多文章了,当然由于ChatGPT本身没有放出paper这些文章都不是完全准确的。今天主要想聊一下它带给我的感受和启发。
ChatGPT改变了什么?
ChatGPT对不同背景的NLPer来说观感是不大一样的,但总体来说,大部分人对于GPT-3之后ChatGPT之前的模型价值是under-estimate的,而对于ChatGPT是over-estimate的。
对很多不太关注大模型的人来说,ChatGPT从根本上改变了他对于大模型的认识,似乎很多他觉得大模型做不了的事ChatGPT做成了,这让人很震撼。据我的观察,很多国内的研究者对于GPT-3以及in-context learning、chain-of-thought的能力是严重低估的,大多停留在“不过是更大的模型”和“玄学prompt”之类的层面上。但我想很多在国外的同仁也不必阴阳怪气,OpenAI对大陆的API限制客观上造成了这个认知代差,并且这个代差并不只存在于中国 vs 国外,而是存在于OpenAI vs 全世界的绝大多数机构。工业界不存在主流认知,学术界更不存在,美国的高校基于大模型API做研究的多一些,但也并不是主流,近年来也美国顶尖高校也罕见押对宝的(Luke Zettlemoyer是个人才)。
但是对大陆的API限制总是有办法绕开的,实际上对于想办法经常玩GPT-3系列的人来说,特别是体验过davinci-002及其后的模型,ChatGPT几乎没有表现出任何新的能力,ChatGPT带来的这种震撼早在之前就感受到了,只不过大多数人把GPT-3.5本身的震撼归功到了ChatGPT上。那么刨除GPT-3.5的功劳,ChatGPT改变了什么?要我说就是用户体验。玩过ChatGPT的人很明显会察觉到,它的回答很全面,不拉踩,像一个滴水不漏的话唠,就好像把GPT-3.5的知识套入了某个pattern/style输出出来,这个pattern/style就是人的说话方式。这是模型的一小步,却是用户体验的一大步。
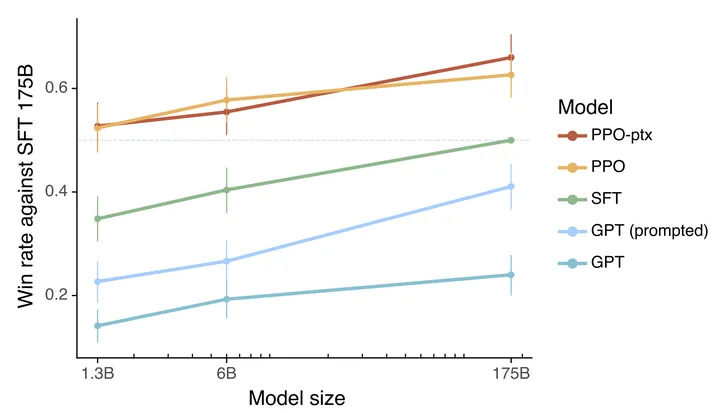
为什么是模型的一小步呢?首先至少是参数更新的一小步,因为align with human的数据量不会很大,根据InstructGPT中显示的只有几万条样本,但这几万条样本对用户体验的提升是多少呢?从下图可以看出来,即使最小的1.3B的InstructGPT也要比175B的初代GPT-3的用户体验好很多,所以说是用户体验的一大步。最近percy liang的HALIE也给出了相关的佐证(眼光真好,在ChatGPT出来之前就意识到了interactive benchmark的必要性)。
ChatGPT没有改变什么?
前面解释了为什么大部分人对于GPT-3之后ChatGPT之前的模型价值是under-estimate的,那么为什么对于ChatGPT是over-estimate的?因为它本质上并没有离通用AI (AGI)更接近,他只是GPT-3.5说人话了。但这个观点要暂时保留一下,因为让GPT-3.5社会化,能够跟人交互,也算是某种程度上的embodied AI,或许还真的可以演化出更高层面的智能,但可能性不太大。因此,ChatGPT并没有本质上改变目前模型的智能水平。
后ChatGPT时代我们能做什么?
从国内来讲,首先当然是复现一个,但是落下的课总要补上,首先要有一个在高质量数据上训练的大模型,还要在大量代码数据上继续训练,还要收集一定数量的instruction让模型理解人的意图,这时如果顺利的话你大概就有了一个text/code-davinci-002了,那么就可以开始RLHF训练自己的ChatGPT或者叫什么其他神仙名字的模型了。当然那个时候最好的算法不一定是现在的RLHF,更有可能是更好的算法来align with human。当然最后一步也不能落下,一切训练好之后,不能发完PR就丢下不管了,你得部署大量的资源把推理时延降下来并且给别人用。
很多人在讨论国内一年之内能否复现出ChatGPT,只要把资源给正确的人一定可以,但问题就在这。那么对于没有足够资源的大多数来说可以做什么呢?一个是前面讲的中间层,在LMaaS场景下用好大模型的API做好一个特定的任务或者应用也会创造很大价值;另一个就是更好的RLHF,这件事未必一定需要特别大的模型,就像前面的图展示的,一个well-aligned 1.3B的InstructGPT也可以远超175B的GPT-3。
如果跳出具体技术路线,从科研方式来讲,ChatGPT对包括我在内的很多人带来的改变应该也是很大的(当然对于paper/award-optimizer选手来说可以毫无影响)。如果冲击不大的话,我现在应该在赶ACL而不是在这里写知乎。冲击来源于哪呢?一方面是对自己过去工作的怀疑,但过去了的就过去了,好歹总能留下点有意义的工作,更重要的是另一方面对未来做研究的方式的冲击。最大的改变在于,不能再刷榜了,或者要刷也得去刷一个类似HALIE这样的interactive benchmark。NLP的研究回归到人机交互是一个回归本质的事情,这应当也是未来几年的大趋势了。走了这么久的路,NLP模型终于走到了真正的人类的面前。从第一人称视角作为用户体验自己打造的模型,肯定比连数据都不看只管刷一个个冰冷的数字要有意思的多。
另一个感受就是,现在一个高影响力的工作更像一个产品,而不是一篇论文。甚至相比于GPT-3 API,基于ChatGPT API来做研究发论文都有一定困难了。相比于研究社区,更大的热情可能来自工业界和投资界,资本对于计算机科学的发展来说可能是最大的推动力。
关于疫情
写到这里耐心逐渐用完,想到哪写到哪,有空再来补。与技术的突飞猛进相对比的是疫情的高歌猛进。人们总是由社会建构所维持的表面秩序获得充分的安全感,现在又通过万物娱乐化获得心理上的愉悦感,但现实永远在那里,炫饭株不止让人骄傲地炫饭,还可能让人得糖尿病。病毒朝哪里变异,我们所在的这艘大船开往何方,没有人知道,你不能指望船长预知一切。
年末, AIGC, ChatGPT, 自然语言处理