ChatGLM-6B:作者Tommyvinny的购买理由与使用体验
文章主题:关键词: ChatGLM-6B, 开源对话机器人, 清华大学, 知识工程
作者:Tommyvinny
购买理由
ChatGLM-6B是由我国清华大学的知识工程和数据挖掘团队开发的一款类似于ChatGPT的开源对话机器人。这款机器人的独特之处在于,它接受了大约1T个标识符的中英文训练,而且大部分都是中文,因此它非常适合在我国使用。
如果你有OpenAI的ID的话,而且你已经用的非常顺畅的话,可以不看了。
如果你手头一块大容量至少8G的显卡,并且拥有一台运行Unraid系统的NAS机器,那么我强烈推荐你尝试一下这款工具。个人使用下来感觉非常便捷,能够显著提升工作效率。例如,在撰写一篇关于某主题的文章时,我能更快地完成初稿,大概缩短了1天的时间。同时,其结构设计也相当灵活,支持与他人的对话和协作,进一步提高了写作效率。此外,我还发现它非常适合处理一些简单的工作任务,比如撰写一篇心得体会,或者制定一个项目计划。在这种情况下,我已经能够实现快速、高效地完成任务,比如写一篇不少于1000字的文章,或者对一个项目进行详细的阐述,而无需花费太多时间。总的来说,这款工具极大地提升了我的工作效率,让我能够更加专注于创作高质量的内容。
由于是在本机运行,没有敏感词,唯一限制你的就是模型的大小和显卡显存的大小。
注意NAS的内存大小,不要少于32G可用,都有独立显卡了,还在乎内存的耗电么?
作为一款AI语言模型,ChatGLM-6B在自然语言处理领域拥有广泛的应用。它的预训练模型可以在多种任务中表现出色,如文本生成、对话系统等。在网站[www.datalearner.com/ai-models/pretrained-models/ChatGLM-6B](http://www.datalearner.com/ai-models/pretrained-models/ChatGLM-6B)上,您可以找到关于该模型的详细信息和使用方法。
在GitHub上,有关ChatGLM-6B的开源项目公开信息表明,该模型完整版在进行推理时需要13GB的显存,然而,其INT4量化版本仅需6GB的显存便可正常运行。这对于个人本地部署而言无疑是一个极大的优势。
以下是部署docker添加方式。
名称:chatglm-6b
存储库:mkaliez99/chatglm-6b:1.1.0
额外参数:–runtime=nvidia
变量 名称 显卡调用 键 NVIDIA_VISIBLE_DEVICES 值 一张显卡就all
在计算机科学领域中,显卡调用模式是一个关键参数,它决定了程序如何使用GPU进行计算。在NVIDIA驱动程序的能力列表中,有两个主要的显卡调用模式:compute和utility。 compute模式主要用于执行大规模的图形处理任务,例如渲染复杂场景或执行深度学习算法。而utility模式则用于执行各种通用计算任务,包括数据处理、图像处理等。这两种模式各有优势,可以根据具体的应用场景选择合适的模式来提高计算效率。
端口 名称 端口主机映射 容器端口 80 主机端口 12808,你可以自己设定自己不用的端口
点击完成后,将开始漫长的拉取环境安装,然后自动下载模型,模型有点大,大约8G左右。
在文件下载完成后,日志界面显示了 Loading checkpoint shards 的信息,其中 100% 表示进度已经达到了 100%。同时,还可以看到当前的检查点数量为 8 个 out of 8,也就是说,所有的检查点都已经准备就绪。此外,还可以看到详细的运行时间以及当前的进度百分比,例如 8/8 [00:24]。这些信息对于理解程序的运行状态非常有帮助。
之后 浏览器输入 ip:12808 就可以快乐的使用了。
外观展示
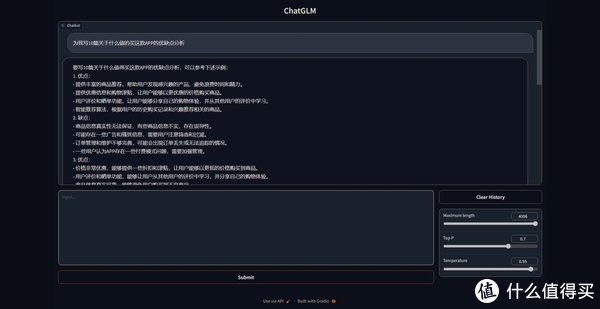
使用感受
我的显卡是X鱼上购买的900元显卡,被动散热,加装了风扇。运行这个生成,基本上秒回。与在线的OpenAI的ChatGPT几乎一致,但是模型是6B的模型,比起AI的30B模型回复的内容质量差距很大,但是日常使用,例如写个心得体会,写一点点的分析,询问一些问题,是完全足够。
总结
个人本地运行,不受限制,不怕被封号,这是唯一的优势。相信以后更大的模型之后,会有更好的效果。有兴趣的可以自己架设起来,让AI助理提高工作效率。
查看文章精彩评论,请前往什么值得买进行阅读互动

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!