AI3.0时代:存算一体超异构,破解算力天花板
文章主题:本文, 自主意识, 存算一体, 超异构
本文源自:南早网
对阵ChatGPT们,存算一体超异构突破算力天花板在即
摘要:国产自主意识爆发,3.14,亿铸率先提出存算一体超异构,引领新一代技术潮流。
AI 3.0时代,国产自主意识爆发
ChatGPT自出世以来,在国内AI界卷起千层浪:
在我国,一些知名的人工智能企业如百度和科大讯飞,都宣称自己具备类似ChatGPT的能力。此外,国家也推出了一系列政策,旨在推动东数西算一体化算力服务平台的建立,以满足我国人工智能运算平台在 大算力服务方面的迫切需求。
而大算力的实现,都需仰仗“大脑”AI芯片。
纵观AI芯片在国内的发展史,我们大致可以将AI芯片国产化分为几个时代。
在AI芯片国产化的初始阶段,随着谷歌推出ASIC芯片,我国国内的企业如寒武纪、灵汐以及华为等也纷纷跟进,针对云端AI应用市场,推出了自家的ASIC架构芯片产品。
在我国AI芯片领域,国产化的进程正在不断推进,目前已经进入了2.0时代。随着英伟达等国际知名企业代表的GPU架构在AI算力芯片上展现出优异的性能,我国的诸多厂商如天数智芯、珠海芯动力、壁仞等也纷纷选择跟进,开始在GPU架构上进行布局,他们主打的是CUDA兼容性,以此探索AI算力芯片的潜力所在。
在前两个时代,我国AI芯片制造商积极应对市场变革,纷纷跟进国际知名企业的发展步伐,致力于研发前沿技术以攻克AI算力芯片难题。
在当前AI技术浪潮中,尤其是ChatGPT等大型模型的推动下,我们已经步入了AI芯片国产化3.0时代。面临日益复杂的地缘政治环境,国产芯片制造企业纷纷强化自身的自主意识,期望能够主动提出并解决芯片问题。
例如,国内AI大算力芯片企业亿铸科技,已为中国的AI大算力芯片一次又一次提出先进的解决方案:
在2020年,亿铸科技便开始探索通过创新架构来突破冯·诺伊曼限制,成为了首个专注于研发基于ReRAM(RRAM)的全数字存算一体AI大算力芯片的企业。这一举措为解决我国AI算力,特别是大算力问题提供了全新的解决方案。
再是今年3.14日,在《电子创新网》“从ChatGPT的角度聊聊存算一体AI大算力芯片”直播中,亿铸科技创始人熊大鹏博士首次提出“用存算一体超异构做AI大算力芯片”的技术思路。
亿铸科技多次提出新解法是因为,种种迹象表明,AI算力难题愈发严重,国产化AI芯片的处境越来越难。
先是算力本身就因摩尔定律失效在加速狂飙,每5-10个月就要翻倍:
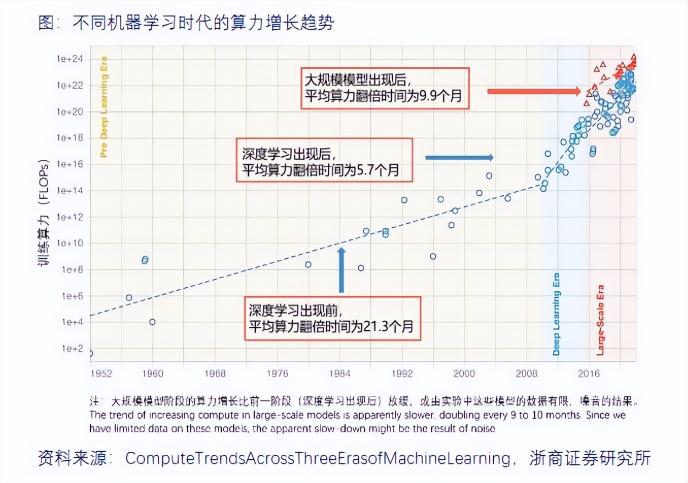 (不同机器学习时代的算力增长趋势 图源:浙商证券研究所)
(不同机器学习时代的算力增长趋势 图源:浙商证券研究所)到2021年,全球计算设备算力总规模达到615EFlops,增速44%。浙商证券预测,2030年,算力有望增至56ZFlops,CAGR达到65%。而这还是ChatGPT还未降临之时,正常的算力需求预测值。
 (全球算力规模及增速 图源:浙商证券研究所)
(全球算力规模及增速 图源:浙商证券研究所)2022年底,ChatGPT来临之后,无疑又将拔高算力的增长曲线:
根据通信世界数据,ChatGPT的总算力消耗约为 3640PF-days (即假如每秒计算一千万亿次,需要计算3640天) ,需要 7-8个投资规模30亿、算力500P的数据中心才能支撑运行。
而这才是参数规模1750亿的GPT-3,除此之外还有参数5620亿的PaLM-E······彼时,算力以及其背后的功耗还能顾得过来吗?
AI算力需求如脱缰的野马,但FPGA、ASIC、GPGPU等芯片本身,已苦于先进制程久矣。据芯粒说表示,目前芯片先进制程升级面临着性能极限、技术极限、成本极限。成本极限具体来说就是,到了5nm以下,建造一座先进制程的晶圆厂动辄需要上百亿美元的投入。
钱是花了,工艺是卷到头了,但能效比提升有限:
传统架构下,由于数据需要频繁地在存储、计算单元间来回跑,随着数据越增越多,“存储墙”、 “能耗墙”、“编译墙”等问题也愈发严重。
现如今,这“三堵墙”已导致大量算力无谓浪费:据统计,在大算力的AI应用中,数据搬运操作消耗90%的时间和功耗,数据搬运的功耗是运算的650倍。
ChatGPT们正提出“极为离谱、不切实际”的算力需求,而芯片们又陷入先进制程升级濒临极限、能效比提升受阻等困境,时代正呼吁着新鲜的血液注入AI大算力芯片。
突破天花板的底气
亿铸科技自发提出的存算一体架构、存算一体超异构计算皆能为AI大算力困局“排忧解难”:
存算一体架构,将存储和计算的融合,能够打破传统架构下的三堵墙,彻底消除访存延迟,并极大降低功耗。同时,由于计算完全耦合于存储,因此可以开发更细粒度的并行性,获得更高的性能和能效。
超异构计算,能够把更多的异构计算整合重构,从而各类型处理器间充分地、灵活地进行数据交互而形成的计算。
简单来说,就是结合DSA、GPU、CPU、CIM等多个类型引擎的优势,实现性能的飞跃:
ü DSA负责相对确定的大计算量的工作;
ü GPU负责应用层有一些性能敏感的并且有一定弹性的工作;
ü CPU啥都能干,负责兜底;
ü CIM就是存内计算,超异构和普通异构的主要区别就是加入了CIM,由此可以实现同等算力,更低能耗;同等能耗,更高算力。另外,CIM由于器件的优势,能负担比DSA更大的算力。
亿铸科技创始人、存算一体 AI 大算力芯片的开拓者熊大鹏博士表示,其好处在两个方面:一是在系统层,能够把整体的效率做到最优;二是在软件层,能够实现跨平台架构统一。
亿铸选择将两大技术结合,即“存算一体超异构”的想法,与苏妈的“系统级创新”不谋而合:在ISSCC 2023,苏妈提出系统级创新概念,即从整体设计的上下游多个环节协同设计来完成芯片性能的提升,并给出使用该概念实现数量级的效率提升案例。
也就是说,若是将存算一体、Chiplet(芯粒)、3D封装等技术同步使用,很有可能带来数量级的效率提升,从而突破性能瓶颈。
亿铸提出这一极具创新度的构想,也是因为其底气十足。亿铸科技拥有实力雄厚的研发、工程及顾问团队:
其核心研发团队成员均为来自国内芯片大厂的资深专家,毕业于斯坦福大学、哈佛大学、上海交通大学、复旦大学和中国科学技术大学等。研发能力覆盖工艺器件、架构设计、电路设计和软件生态等全链条;
其工程团队核心成员平均拥有25年以上的高端集成电路设计和量产经验,有着丰富的应用和产品化实战经历。
基于此,作为首发存算一体超异构概念的亿铸科技,提出了自己的技术畅想:
若能把新型忆阻器技术(RRAM)、存算一体架构、芯粒技术(Chiplet)、3D封装等技术结合,将会实现更大的有效算力、放置更多的参数、实现更高的能效比、更好的软件兼容性、从而抬高AI大算力芯片的发展天花板。
 (关于存算一体+超异构 做AI大算力芯片的技术畅想 图源:亿铸科技)
(关于存算一体+超异构 做AI大算力芯片的技术畅想 图源:亿铸科技)一方面,ChatGPT等大模型的发展对算力提出了史无前例的要求,吞噬着算力与能源;
另一方面,ChatGPT也为存算一体架构、超异构等技术带来核级推动力。无论是大厂和初创公司,都在为突破算力瓶颈“奋力一搏”。基于亿铸科技有最适合大算力的器件(RRAM),再加上3D封装和Chiplet等技术,熊大鹏博士表示,亿铸科技能够为解决存储墙、能耗墙问题带来杀手级的硬件解决方案。
在摩尔定律几近终结、ASIC、FPGA以及GPGPU架构能效比难以提升的当下,亿铸科技率先提出“存算一体超异构架构” 这一全新的技术发展路径,为我国AI大算力芯片进一步发展,增添了新的动能。

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!