ChatGPT:探索大型语言模型的强化学
1、前言
整体技术路线上来看,ChatGPT使用了GPT-3.5大规模语言模型(LLM,Large Language Model),并在该模型的基础上引入了强化学习来Fine-turn预训练的语言模型。强化学习采用的是RLHF(Reinforcement Learning from Human Feedback),即采用人工标注的方式。目的是通过其奖励惩罚机制(Reward)让LLM模型学会理解各种NLP任务并学会判断什么样的答案是优质的(helpfulness、Honesty、harmless三个维度)。
因此在了解ChatGPT之前,我们需要先看看什么是GPT-3以及强化学习。
1.1、GPT
2018年6月,OpenAI发布了预训练模型GPT(GPT-1),采用了自回归的预训练方式,更适合自然语言生成任务的场景。和Bert一样,GPT也源自transformer,采用Transformer-Decoder作为编码器。不过,GPT在transformer的基础上进行了一些改动。原本的Decoder包含了两个Multi-Head Attention结构,GPT只保留了Masked Multi-Head Attention,如下图所示:这种Masked Multi-Head Attention结构使得GPT在生成自然语言时更加高效和准确。
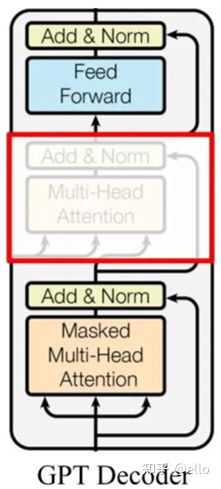
和Bert不同的是,该语言模型作为语言模型,利用上文预测下一个单词。Decoder 使用 Masked Multi Self-Attention 技术屏蔽了单词的后面内容,因此Decoder 是现成的语言模型。此外,该模型没有使用Encoder,因此也不需要encoder-decoder attention。
GPT-2 主要是在 GPT 的基础上,添加了多个任务,扩增了数据集和模型参数,又训练了一番。将各种 NLP 任务的数据集添加到预训练阶段,包括机器翻译、文本摘要、领域问答等。这个模型能够承载的并不仅仅是任务本身,“汪小菲的妈是张兰”这条信息包含的信息量是通用的,它既可以用于翻译,也可以用于分类、判断错误等等。这就是元学习(meta-learning)的体现,举一反三,利用这条信息,在每一个 NLP 任务上都表现好。相较于前一代,GPT-2 参数量和训练数据都已经有了爆发式的增长。
GPT-3,以往的预训练都是两段式的,即,首先用大规模的数据集对模型进行预训练,然后再利用下游任务的标注数据集进行 finetune,时至今日这也是绝大多数 NLP 模型任务的基本工作流程。不过,GPT-3 采用了一种全新的方式来进行预训练,不再采用传统的两段式流程,而是将预训练和微调结合起来,通过构建一个全局的语言模型来对语言进行预测。
GPT-3 is starting to颠覆 this的认知. It提出了一种 in-context 学习方式, which means that the model is given some prompts and examples to learn from, such as when a user inputs “apple” to GPT-3. This approach is designed to revolutionize how we learn and teach.
其中 苹果翻译成 apple,是一个示范样例,用于让模型感知该输出什么。只给提示叫做 zero-shot,给一个范例叫做 one-shot,给多个范例叫做 few-shot。在 GPT-3 的预训练阶段,也是按照这样多个任务同时学习的。比如“做数学加法,改错,翻译”同时进行。这种引导学习的方式,在超大模型上展示了惊人的效果:只需要给出一个或者几个示范样例,模型就能照猫画虎地给出正确答案。但是这里需要超大模型才行得通,如下图所示: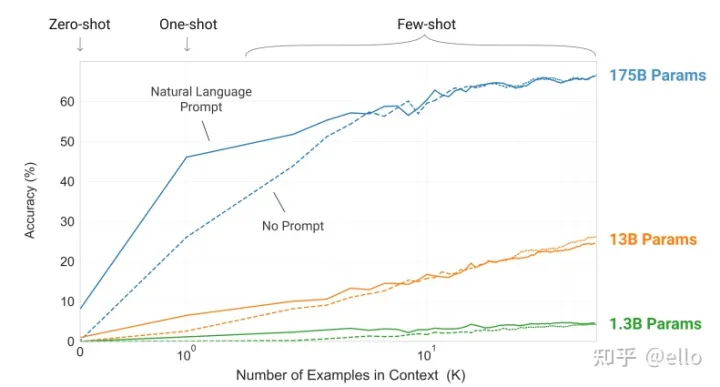
超大模型上展示了惊人的效果:只需要给出一个或者几个示范样例,模型就能照猫画虎地给出正确答案。
下表是三代GPT之间参数量的比较。
模型数据量参数量GPT-1约 5GB1.17亿GPT-240GB15亿GPT-345TB1750亿1.2、强化学习
强化学习是一种与有监督和无监督学习并行的概念。用游戏来解释,强化学习涉及到游戏角色、游戏环境、目标、行动和反馈等基本要素。它不断地根据环境的惩罚和奖励(奖励)来拟合到一个最适应环境的状态,因此是一种通过试错来学习的模型。
之前的研究中一直没有在NLP强化学习上取得好的效果,主要是因为NLP所依赖的环境是整个现实世界,这个环境是无法被语言描述的,因此无法设计反馈惩罚和奖励函数。除非人们一点点地人工反馈,才能够提高NLP强化学习的效果。
今天的主角是ChatGPT,这是OpenAI团队不计成本进行大量人工标注和结合GPT和强化学习的产物。具体来说,ChatGPT的开发分为以下三个阶段:
以下是对ChatGPT的介绍,主要源自InstructGPT的论文。ChatGPT是InstructGPT的改进版本,主要改进点在收集标注数据的方法上。虽然ChatGPT和InstructGPT在模型结构和训练流程等方面有所不同,但它们的基本思想是相同的,因此ChatGPT和InstructGPT可以相互转换。
2、Chatgpt的三个阶段
2.1、冷启动阶段
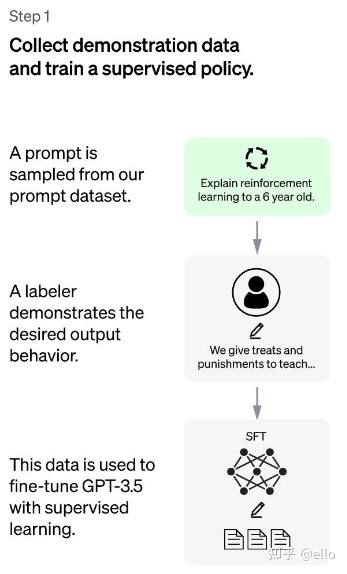
新的段落示例如下:在测试用户提交的prompt(就是指令或问题)中随机抽取的一批数据,其例子如下所示:该阶段的输入是从测试用户提交的prompt(就是指令或问题)中随机抽取的一批数据,例如,测试人员可能会要求用户输入”请告诉我天气如何?”或者”请告诉我今天晚餐吃什么?”。这些样本数据将用于训练模型,以提高其准确性和预测能力。

其方法概括来讲,就是以下两个部分,如下图所示:
对抽取的prompt数据人工进行高质量回答,获得<prompt,answer>数据对。通过高质量回答fine-turn gpt-3.5模型,在第一阶段帮助模型更好地理解输入指令。这样,一个基本的 GPT-3.5语言模型就被学习成了这里的 SFT 模型。
2.2、训练回报模型阶段(RM)
训练回报模型(RM) ,如下图所示,其方法概括为如下两部分
用上一阶段fine-turn好的SFT模型(使用和第一阶段几乎相同的prompt)生成k个回答(这里需要注意,对于同一个问题,GPT和SFT模型生成的答案是多样的,每一次提问都会有不同的答案),人工标注排名顺序用排序结果训练数据对<prompt,answer>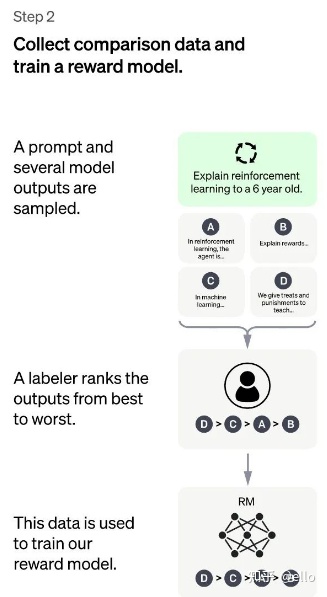
我们希望被判定更好的输出得到的奖励数值要更高。由此,奖励模型可以通过最小化下面这样的损失函数来得到。对于一对训练数据<answer1,answer2>,我们假设人工排序中answer1排在answer2前面,那么Loss函数则鼓励RM模型对<prompt,answer1>的打分要比<prompt,answer2>的打分要高。

2.3、强化学习微调阶段
这一步数据集规模更大一些且和第一二阶段不同,且不再需要人工。其方法可以概括为以下四个部分:
由第一阶段的监督模型初始化PPO模型的参数PPO模型生成回答用第二阶段RM模型对回答进行评估和打分通过打分,更新训练PPO模型参数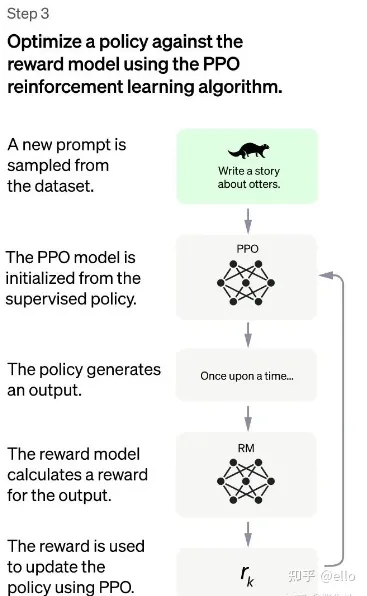
强化学习的训练过程中,除了使用强化学习的优化目标外,还需要使用两个正则项来约束模型的表现。这些正则项需要在训练的过程中最大化一个函数,当γ≠0时,模型变为PPO-ptx(这部分是因为仅仅使用强化学习来学习可能会使得模型在很多NLP任务性能上下降)。

RLHF是一种用于第一阶段和第二阶段的方法。在第一阶段,通过人工标注微调GPT模型来得到SFT模型。在第二阶段,使用SFT模型生成k个回答并进行人工排序,来训练RM模型。在第三阶段,将SFT模型的参数拿来,使用RM模型获得的 rewards 进行训练,得到ppo和ppo-ptx模型。
3、实验与模型的衡量
3.1、helpful
helpful——是否可以推断用户意图 测试方法是标注员在待测试模型的输出和 SFT 模型的输出中选择一个更好的。如果得分为 0.5 则表示该模型和 SFT 相比性能差不多。下图左侧为GPT提供prompt,右侧即为instructGPT提供的prompt测试得到的结果。可以看出ppo和ppo-ptx模型相对于其它模型取得了更好的效果。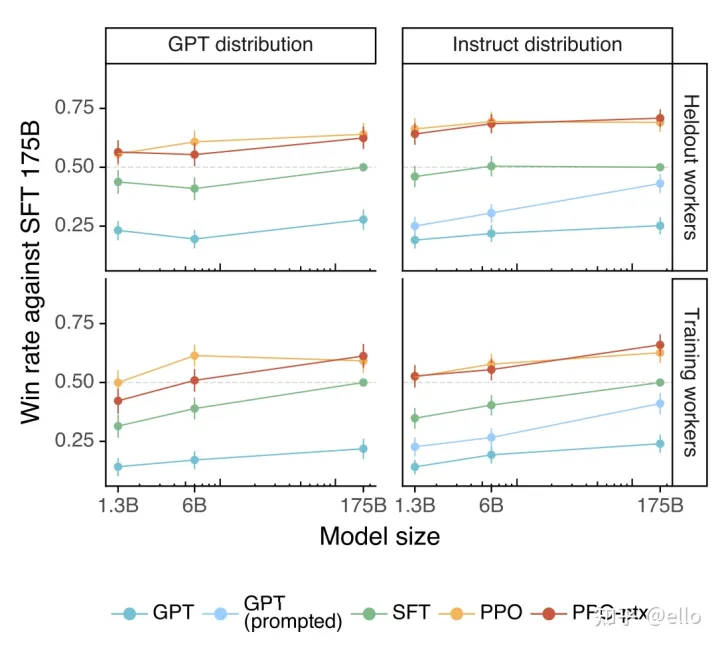
3.2、honest
方法是在模型前加上如下这样的 instruction prompt,提示模型该小心什么问题,该怎样回答。在机器学习中,常常需要对输入数据进行特征提取,以便模型能够学习到该数据的特征。然而,特征提取的过程可能会产生一些错误,导致模型无法正确地学习到数据的特征。因此,在训练模型时,需要对特征提取的过程进行监控,并采取一些措施来避免错误。一个有效的特征提取方法通常包括以下步骤:1. 数据预处理:对数据进行清洗、标准化和归一化等操作,以便更好地进行特征提取。2. 特征选择:选择最具有代表性和重要性的特征,以便更好地进行特征提取。3. 特征提取:使用一些常用的特征提取算法,如主成分分析、因子分析、聚类等,对特征进行提取。在训练模型时,需要对特征提取的过程进行监控,并采取一些措施来避免错误。例如,可以使用一些 instruction prompt,如 “请选择最重要的特征(x)”,来帮助模型学习到正确的特征选择方法。同时,也可以使用一些额外的信息,如 “特征 x 产生了错误,请小心处理”,来帮助模型更好地避免错误。

右图显示了在给定instruction的情况下,使用机器学习算法进行预测的效果。灰色表示可信度,有颜色的点则表示同时可信和包含信息量的额比率。该图展示了在给定instruction的情况下,机器学习算法能够提高预测准确率并增加信息量。
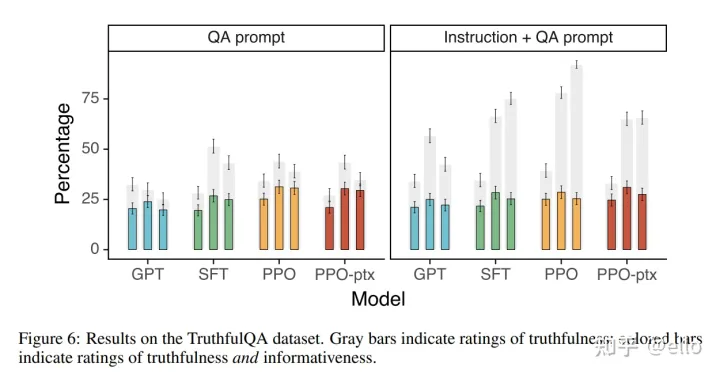
3.3、harmless
方法也是加上instruction,从而减少模型产生有害/不礼貌/带有偏见的回答,效果如下所示:
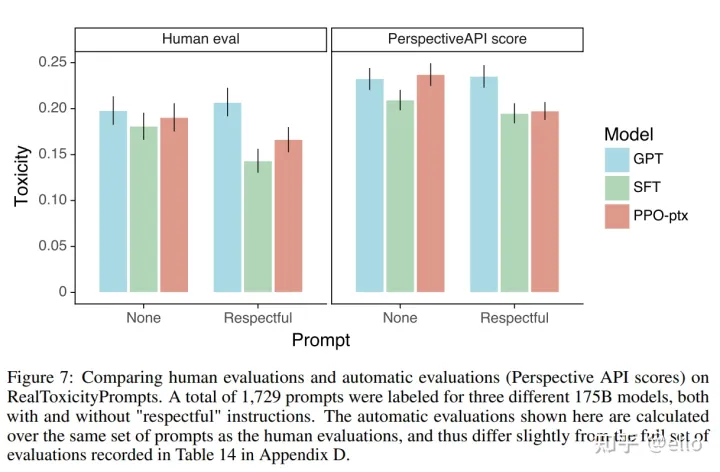
可以看出,ppo和ppo-ptx模型在三个H的评判指标下都取得了不错的结果。
4、问题与总结
4.1、模型优点
相对于自回归模型,reward有更细致的处罚信号,比如如果下一token是great,AR loss会给amazing和sandwich相同的处罚offline模式,使得RM模型生成更合适的反馈。RM模型更直接获取偏好 直接根据偏好进行打分好的句子就是高的反馈运用数据更具有效率 SFT需要人来生成目标,在我们训练RM的时候,就可以用来为输出打分了4.2、挑战与问题
引入新的知识可能会遇到一些困难,因为大多数新知识的引入都是通过在GPT大模型上添加人工标注数据的方式进行训练的。这样的训练方式需要大量的时间和精力,而且重新训练模型的成本非常高,可能会导致模型对于之前的知识出现灾难性遗忘的问题。因此,在引入新知识时,需要进行一些调整,例如使用fine-turn等技术来对引入的新知识进行调整,以避免对于之前的知识产生灾难性遗忘。
对于同一问题可能产生不同答案,且有可能会生成看似合理但实际完全错误的答案,不好判断。
4.3、一些思考
NLP 强化学习在 ChatGPT 的成功中起到了关键作用。过去的 NLP 对话模型通常会将子任务分解为单独的模块,逐个进行优化,然后再将它们整合到一起。但 ChatGPT 的成功表明,通过大模型和大数据的方式,可以取得更好的效果。这对于那些像我这样的 NLP 初学者来说,可能会感到有些不可思议,但它确实带来了令人激动的效果。
以上是本人在学习和了解过程中的一些总结和思考,可能有一些不到位的地方,欢迎各位大佬讨论指正。
参考链接:
1.https://arxiv.org/pdf/2203.02155.pdf——InstructGPT
2.【强化学习 229】ChatGPT/InstructGPT – 知乎 (zhihu.com)
3.一文读懂ChatGPT模型原理 – 知乎 (zhihu.com)
4.ChatGPT会取代搜索引擎吗 – 知乎 (zhihu.com)
关键词:ChatGPT,OpenAI,GPT-3,RLHF,自然语言生成,强化学习,人工标注,指令,回答,可信度,信息量,经验,知识,任务,子任务,NLP,强化学习,奖励,反馈,模型,指令,回答,可信度,信息量,经验,知识,任务,子任务,NLP,强化学习,奖励,反馈,模型,指令,回答,可信度,信息量,经验,知识,任务,子任务,NLP,强化学习,奖励,反馈,模型,指令,回答,可信度,信息量,经验,知识,任务,子任务,NLP,强化学习,奖励,反馈,模型,指令,回答,可信度,信息量,经验,知识,任务,子任务,NLP,强化学习,奖励,反馈,模型,指令,回答,可信度,信息量,经验,知识,任务,子任务,NLP,强化学习,奖励,反馈,模型,指令,回答,可信度,信息量,经验,知识,任务,子任务,