ChatGPT:超能还是坑?揭秘其优势与不足,未来搜索趋势何在?🔥
文章主题:ChatGPT, 人工智能, 搜索引擎, 不足

这两天,ChatGPT模型真可谓称得上是狂拽酷炫D炸天的存在了。
讲真,NLP这块,这两年把 Bert 引领的预训练 + finetune 的技术模式榨干之后,业界凉了许多。ChatGPT 真的是给 NLP 这堆快要烧尽的火又添了一桶油。
🌟 ChatGPT 已经成为了人工智能领域的耀眼明星,它颠覆了人们对传统模型的认知,让人们不得不重新审视这一领域。提到AI,脑海里瞬间浮现出两个鲜明的对比:一个是ChatGPT的卓越智慧,另一个则是那些曾经被戏称为“人工智障”的过时表现。
很多人都在讨论如下问题:
ChatGPT 会取代搜索引擎吗?
ChatGPT 是不是要让程序员都失业啊?
ChatGPT 出来了,google 和百度两家是不是要凉啊?
你看,还上热搜了:

趁大家都在兴头上,我来浇一盆凉水。分析一下 ChatGPT 到底有哪些不足?
如果还有小伙伴没有看过 ChatGPT 原理的,来看看这篇

大家在玩 ChatGPT 的过程中依然遇到了一些问题和现象
一、ChatGPT 突然就卡壳了
当你与ChatGPT互动时,有时可能会遭遇模型暂时停滞的困扰。这种现象可能源于模型偶尔产生的异常输出,表现为一个微小的终止符号。虽然概率极低,但确实可能发生,需要我们理解并适应。优化你的沟通体验,让它更流畅运行。记得,偶尔的小故障是技术进步的一部分哦!📚💻
GPT-n系列模型都是基于自回归方式构建的,在输出对话结果的过程中,是依次按序输出每一个字符的,并设定了终止符<eos>,如果在某一个时刻,模型输出了该字符,则表明输出句子完毕。
毕竟,ChatGPT 依旧是基于概率统计原理构建的模型,必然存在一定极其微小的概率,突然就输出到了一个 <eos> 字符,导致终断输出了。
不过好在 ChatGPT 的多轮对话能力非常强大,只要给出继续的指令,它就能连续输出。
二、ChatGPT 出现了事实性错误
宫廷玉液酒我们都是知道,这是赵丽蓉和巩汉林的小品台词,用户在这里输入“宫廷玉液酒”,其意图也是想和 ChatGPT 对暗号,看看能不能说出“一百八一杯”,用来测试到底是不是中国大陆的人。

🎨ChatGPT误解密码,🔥误导为抽象概念,混淆视听!明明是独步江湖的华夏美酒🌟,它却给出了错误的答案,让人啼笑皆非。这不是严谨的学术交流,而是滑稽的智能闹剧。下次求助,可得找对专家哦!👩🏫💡
换句话说,ChatGPT 模型无法分清真实和虚构。
它不知道宫廷玉液酒是什么,但是名字和其它一些中国白酒比较像,然后照猫画虎地编了一段白酒的介绍。
电线是谁发明的?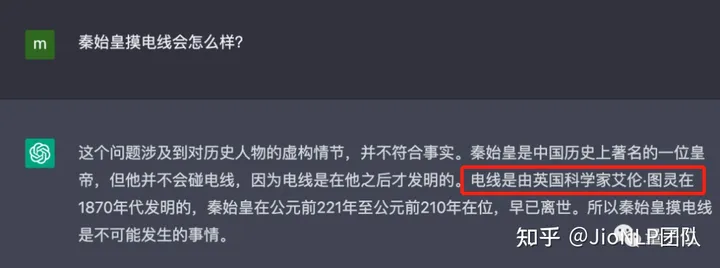
电线怎么成了图灵发明的了?这是事实性错误。
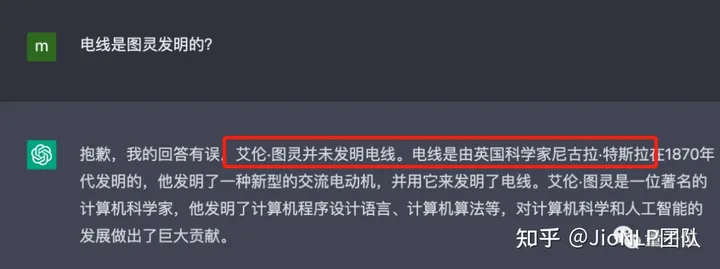
ChatGPT 模型可以马上改口反悔,说出正确的答案,电是特斯拉发明的。
这说明,模型训练过程中,语料确实包含了真实的、正确的信息的。但是在推理阶段,它还是犯错了。
而且这样的错误,伴随着大量的用户测试,也越来越多。大家发现它并不是一个100%稳妥可靠的知识库。
这基本可以得出结论:ChatGPT 无法完全替代搜索引擎。
它更适用于一些务虚的任务,比如写小说、写诗歌、搞辩论、写汇报材料、写公文材料(别打我)
三、ChatGPT 没有与实时信息的关联
🌟虽然ChatGPT以其先进的AI技术引发了广泛关注,但它在信息获取上存在局限性。💡尽管具备自我意识,它的知识库更新至2021年,无法即时获取并传递最新的资讯。🔍由于缺乏搜索引擎的集成,它无法像传统工具那样迅速捕捉和分享最新数据,这对用户来说是个不小的遗憾。
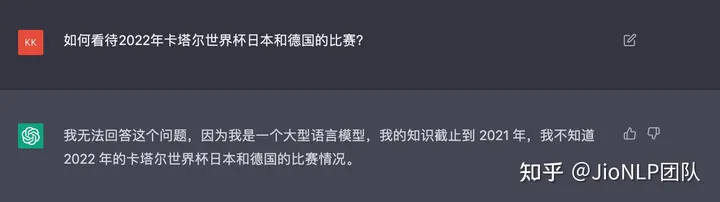
这同样说明,ChatGPT 无法替代搜索引擎。反而更适合作为搜索引擎入口的一个非常好的优化。
🌟搜索引擎优化秘籍🔍:提升搜索体验,直达答案!💡在信息海洋中畅游,传统的Google或百度搜索方式往往需要用户费力输入关键词,然后大海捞针般浏览网页。但这并非终点,我们期待的是瞬间直达,无需繁琐步骤就能获取所需信息。🚀想象一下,只需轻轻一按,答案就像磁铁一样自动吸附,省时又高效。这就是未来搜索引擎的愿景——智能搜索,让知识触手可及!📚优化搜索体验,不再让用户大海捞针,是技术进步的一大挑战,也是SEO专家们的使命。让我们携手,共同期待那一天的到来,让每一次查询都像享受一次贴心的服务。🤝记得,下次在键盘上敲击时,不妨想象一下那个瞬间反馈的未来,让搜索变得更简单、更智能!💪#搜索引擎优化 #智能搜索 #知识获取体验
ChatGPT 有一个很好的功能,它可以润色文字。
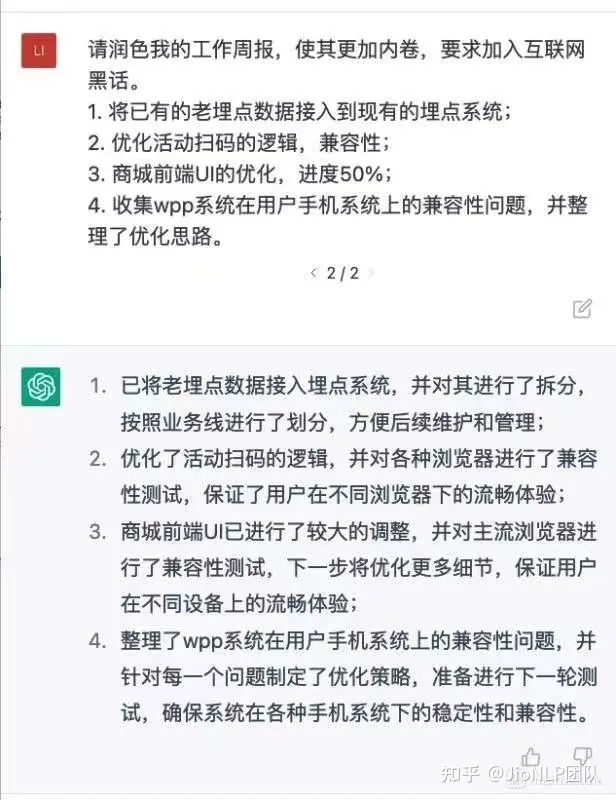
🌟ChatGPT的潜力无限,它能巧妙地解析网络信息,提取精华,为用户提供定制化的阅读体验。无需繁琐筛选,只需一键,用户就能获得最相关、最具吸引力的内容摘要。这不仅提升了效率,也让获取知识变得轻松愉快。SEO优化已融入其基因,帮助内容更好地触及搜索引擎和潜在读者。🌍🚀
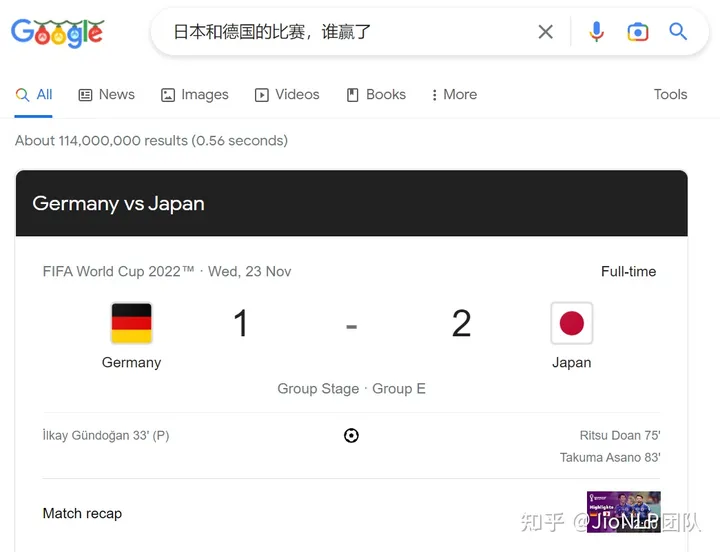
所以可以得出结论,ChatGPT 非但不能替代 Google 和百度,反而,Google 和百度可以研发 ChatGPT 进一步优化搜索引擎,甚至可以把失去的搜索份额重新夺回来。
四、ChatGPT 没有思考能力
Google 前段时间有员工声称感觉到模型具备了意识。
这我感觉不应当叫做缺陷,因为它学习的并非真实的世界,而是那个 reward 模型。
模型并不理解什么叫小猫,也并不真正理解什么叫楼房。它没有触觉、没有知觉。
当然,它也无法观察世界,进行思考和创新。所以,我一直在想,什么时候,模型能够带上传感器,能够真实地感觉一下这个世界,那时的模型应该才能够有更加精准的意识。
甚至,带上一些人类不具备的传感器能力,比如,红外线和紫外线传感器,是不是就能够探知一些人类很难想象的另一个世界。
五、ChatGPT 的其它缺陷
我在知乎上看到有一些用户在苛责 ChatGPT 偶尔也会宕机,也会输出一些低质量的歌词、诗歌、小说等等。
这些缺陷并不是真正的困难和难点,个人认为是太过苛责 ChatGPT 了。
GPT-3 的局限性原因分析
一、有多少人工就有多少智能
在 ChatGPT 出来之前,NLP 业界可谓说已经到了一个冰点了。大家普遍都意识到了当前人工智能技术的一个巨大的缺点,那就是太过依赖标注数据。
比如,拿比较成熟的机器翻译模型为例,你没有上千万的双语预料对,那训练出来的模型是充满bug,不堪一用的。此外,语言是不断演化的,你的模型的语料也需要不断更新,以适应人们的需求。
再比如,天池平台上的 AI 竞赛,有非常多的比赛任务,数据量就只有几万条,几十万条。而任务本身又是极具挑战性的开放性问题,这就造成了很多参赛团队和选手都在一个很窄的赛道里拼命地卷。实在太缺数据了呀!!
人工标注数据,不论你标注了几百条,还是上百万条,抑或辛辛苦苦标了上亿条,只要你方法没变,依然是人工来做,那本质就没变。
这就类似于人力车和蒸汽机的区别,属于代差。
ChatGPT 虽然出产自 OpenAI——一家财大气粗的 AI 科技公司,该模型的最核心部分,也就是利用NLP+强化学习打造的奖励与惩罚reward模型,实际上也是由大量的人工进行标注训练的。
我喜欢将奖励与惩罚reward模型称为 reward 母体,因为和《黑客帝国》里的 母体 matrix 的概念、作用太相似了。

ChatGPT 模型的能力上限,很大程度就是由这个 reward模型决定。它的拟合能力越接近真实的世界,ChatGPT 也就越能够完成令人惊艳的推理、判断、感知操作。
就像我们需要巨量的语料去完成机器翻译任务一样,reward模型也同样需要巨量的语料来拟合真实世界。这个代价是十分巨大的。
reward 模型拟合不好的地方,就是人们观察到 ChatGPT 模型效果糟糕的地方。那是下一个缓慢爬坡的过程。
二、对标注人员的高要求
惯常认知里,AI模型的数据标注员是个低端的职业。制作一个猫狗分类器,标注员的主要工作就是对每一张图片包含了猫、还是狗进行一个分类,小学生都能做。
然而,ChatGPT 模型里,它所能完成的工作甚至达到了,做高等数学题这种程度。模型输出的结果是否真实可靠,需要reward模型进行评价和反馈。这时候,如果数据标注员没有高等数学知识,我想很难保证模型的精准。
有人猜测,ChatGPT吸纳了 Stack Overflow 里大量的优质答案作为数据,但 Stack Overflow 本身也是由人工一点点构建起来的巨型大厦。
高要求,也就意味着,评价困难。模型质量的提升也较为困难。
三、再大的模型也不是无限
GPT-n 系列模型一代比一代大,从最早大家觉得几个亿的参数和几个G 的文本数据量就叫大模型。到了现在,GPT-3 和 3.5 里,模型参数达到了上千亿,数据量也达到了上万亿规模。
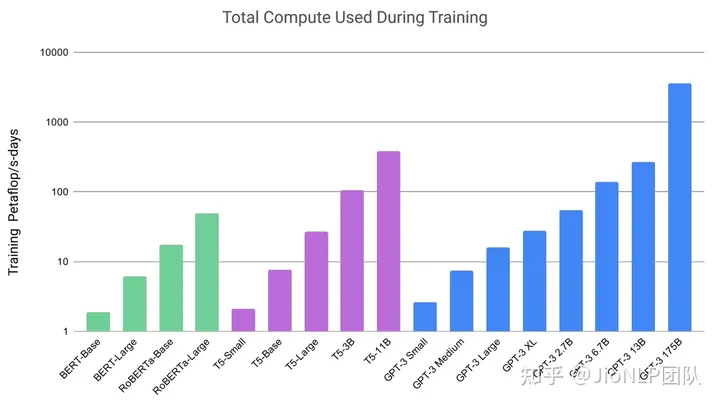
我们也看到了 ChatGPT 里并非存得下全世界的所有知识,而用户提问则是对全世界所有知识的一个采样,那绝对是一个无限的范围。
吾生也有涯,而知也无涯。以有涯随无涯,殆已!
换在模型上,则是:
模型也有涯,而知也无涯。以有涯随无涯,殆已!
作为一个模型,能够做到这种程度,我必须给100分,因为它已经克服了太多的 NLP 之前的难题,诸如多轮对话的连贯性、指代消岐、讽刺、正话反说等等。
我们夸一个小孩聪明,只需要他回答出一个精彩的答案;我们夸一个模型牛逼,却需要它方方面面都给出精彩的答案。
毕竟 ChatGPT 只是一个有限的模型,它不是全宇宙知识汇聚的神。不能要求它掌握全世界知识,一旦出错就把 ChatGPT 贬为人工智障。
但确实,一个需要发展的方向是,如何让模型能够持续更新知识,查询知识。牵着搜索引擎和互联网的牛鼻子,而非把整头牛都抱在怀里。
(欢迎关注我的公众号JioNLP,一个NLP抱团取暖的地方,开源软件JioNLP 在Github,目前star数1.7k)



AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!