【ChatGPT系列报告】解析Midjourney的成长之路
我们将“AI+传媒”的研究框架体系定义为“通用大模型”+“行业小样本”的技术架构,“AI+传媒”在应用层表现效力优劣的关键取决于通用大模型对垂直应用的适配程度及迭代速度,
1、适配程度是指:多模态的输入及输出是否匹配应用层的输入及输出。比如GPT-4属于“图+文”多模态输入+“文”单模态输出,因此输入模态为“图或文”且输出模态为“文”的垂直应用更适配GPT-4。
2、迭代速度是指:应用层产生的“行业小样本”的数据量是否匹配大模型的迭代要求。根据我们对GPT模型的理解,比如BingAI产生的“行业小样本”源自Bing的搜索结果,ChatGPT产生的“行业小样本”源自用户的反馈和互动。因此我们认为,对于超出GPT所使用的预训练数据库范围(2021年9月前)的事实性表述,BingAI反馈的是搜索的结果,ChatGPT反馈的是用户主动的观点,BingAI反馈的效果比ChatGPT更好。
我们认为“行业小样本”的价值取决于数据数量及数据质量,数量大且质量高(多模态)的应用场景复用及迭代AI能力的效力更强,因此更进一步理解我们的研究框架,我们将“行业小样本”的结构分层(中层小模型+下层应用及内容),并将“行业小样本”的结合方式分类(调用+训练):
1、“行业小样本”的数据集来自小模型或应用及内容:AI产业链包括上层大模型、中层小模型、下层应用及内容,包括应用及内容直接接入大模型或通过小模型接入大模型两种方式,即“大模型+应用及内容”或“大模型+小模型+应用或内容”,其中具备特定功能的AIGC软件产品及MaaS我们理解为“小模型”+“应用”的技术范式,本身具备较高质量的AI能力,若接入匹配的多模态大模型,有望实现能力上的质变突破。
2、“行业小样本”的结合方式包括“能力调用”及“能力训练”两类:
(1)“能力调用”是指下游垂类场景直接调用通用大模型的通用能力,并基于垂类场景内产生的特性化数据不断提升调用能力在垂类场景内的适配程度。我们认为现阶段下游应用及内容主要采取此类方式接入大模型能力,此类方式可高效快速调用大模型先进能力,在时间上及成本上具备优势。我们认为“能力调用”匹配“AI+传媒”的第一层利好,即通过AI降本增效,大幅提高数据及内容的供给量。内容产业本质由供给决定需求,因此内容供给量的明显提升将有效带动传媒基本面拐点及增量空间出现。
(2)“能力训练”是指下游垂类场景将通用大模型针对特性化数据集进行再训练,从而形成垂类场景专属大模型。例如彭博社利用自身丰富的金融数据源,基于开源的GPT-3框架再训练,开发出了金融专属大模型BloombergGPT。我们认为“能力训练”匹配“AI+传媒”的第二层利好,即下游垂类场景本身的数据或内容反过来“再训练”通用大模型(或开源大模型),形成传媒内容场景专属大模型,形成更稳定且高质的内容输出。我们认为训练难度文本<图片<视频<影视<游戏,且内容数量逐步递减但内容质量逐步递增,即偏后端的影视、游戏在内容数量上训练量级不足,因此高质量的内容形态首先通过“能力调用”输出AIGC内容,再将AIGC内容“再训练”大模型以解决高质量内容数量不足的问题(合成数据“再训练”范畴)。从投资的角度,按照我们的研究框架,传媒对应垂类场景的“行业小样本”,其核心价值取决于数据与内容,第一层对应数据与内容的输入模态是否匹配大模型的输出模态;第二层对应数据与内容的数量及质量是否匹配大模型的能力再训练:
1、按照“模态匹配”的逻辑,AI+文本/虚拟人预计率先兑现案例及业绩,其次AI+图片可通过“大模型”+“小模型”组合方式实现(如GPT+StableDiffusion、GPT+Midjourney)。随着未来GPT-5提供更多模态的输入及输出,下游垂类场景的适配范围有望扩大,通过“能力调用”适配的应用及内容场景更为丰富,因此后续“AI+视频/影视/游戏”的案例兑现度存在新的催化空间。
OpenAI最新发布的GPT-4核心特征包括:(1)多模态输入(图+文),单模态输出(文),可以阅读并总结论文内容、解答较高难度的物理题目、具备较强的OCR能力(如识别网页草稿并按要求反馈网页代码)、理解人类社会常识;(2)具备长文字处理及推理判断能力,GPT-4上下文上限约2.5万字,允许使用长格式内容创建、扩展对话以及文档搜索和分析等,能够阅读并记忆更多信息,且具备更高的推理判断能力;(3)可靠性大幅提升,分辨能力提高,有效减少“虚构”或“有害”信息输出。2、按照“能力再训练”的逻辑,AI+内容/IP预计空间及价值更大,其价值核心取决于数据与内容/IP的数量及质量的高低。微软本周发布的DeepSpeed-Chat大幅提升大模型预训练速度并大幅降低训练成本,我们认为最核心意义为大幅降低垂类场景专属大模型的训练门槛,小模型层及应用层有望明显受益。掌握数据及优质内容(多模态数据)的下游场景具备核心竞争力,因此内容及IP(版权)的价值有望重估。
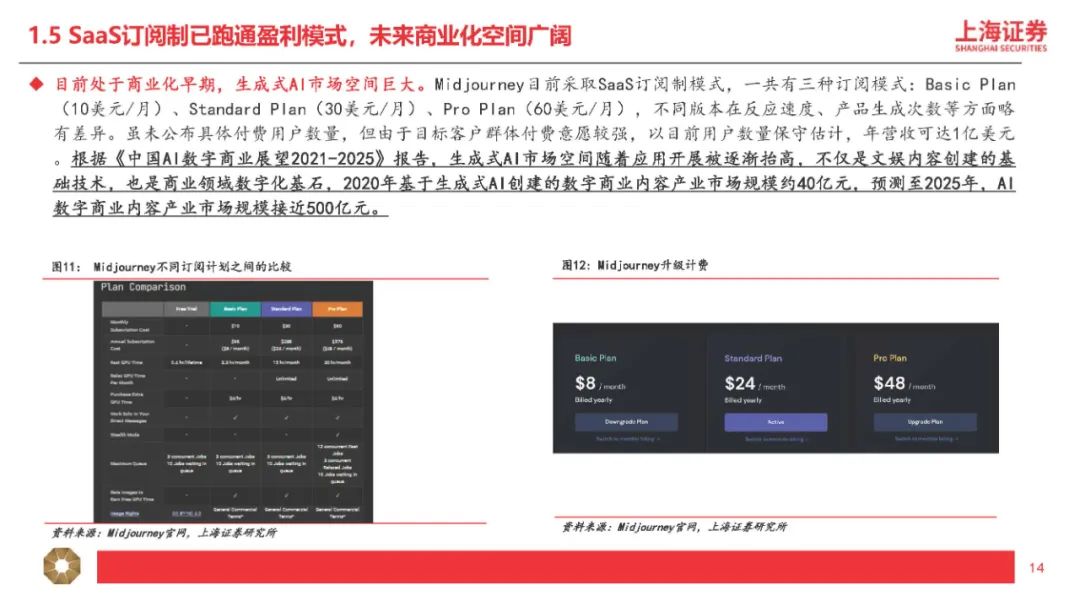
DeepSpeed-Chat集成预训练语言大模型完整三个步骤,其中针对第三步RLHF训练集成了高效且经济的DeepSpeed-RLHF系统,使复杂的RLHF训练变得快速、经济并且易于大规模推广(相比现有系统提速15倍以上,且大幅降低算力要求及成本)。本文将选取国外AI图像生成领域的龙头之一进行解析,Midjourney是国外一款搭载在Discord社区上的图像生成应用,通过差异化产品定位拥有了早期数据积累及活跃社区,截至2023年3月在Discord上的用户数超1300万,是目前用户数最多的服务器,年营收约1亿美元。公司团队成员仅11人,人效极高,团队成员及顾问拥有AI技术及产品创业的复合背景,从不同纬度赋能公司发展。
基于CLIP及Diffusion的开源模型构建专属闭源模型,数据飞轮快速构建护城河。Midjourney通过参考CLIP及Diffusion开源模型的基础上抓取公开数据进行训练,从而构建自己的闭源模型以适应行业技术的飞速发展。此外,通过收集用户反馈及数据标注,Midjourney不断迭代模型,在ValueChain上占据多个数据层、模型层、应用层整个技术栈。
以艺术风格建立差异化竞争优势,具备广阔的用户基础,目标客群付费意愿强烈。Midjourney拥有多种不同风格可供选择,艺术风格在市场上具备差异化优势。prompt简短生成效果惊艳,具备较强商业性,锁定基数大付费意愿强的创意设计目标客群,被大量实践证明能显著提高工作效率。2022年3月V1发布时仍参考了很多的开源模型,同年4月、7月、11月分别发布V2、V3、V4,其中V4补充了生物、地点等信息,迭代出了自己的模型优势,增强对细节的识别能力及多物体、多人物的场景塑造能力。2023年3月,在经历多次更新后的MidjourneyV5版本解决了一些技术难题,完成了跨越性的突破。
Midjourney与Discord双轮驱动,激励用户点赞积累标注数据。Discord为Midjourney的启动提供了绝佳的社交体验平台,成功将其带入了大众市场。一方面Discordbot降低了用户使用门槛;另一方面,图片创作是一个在讨论中不断迭代的过程,欣赏其他用户的作品有也助于激发灵感。此外,Midjourney通过赠送免费使用时间来激励用户点赞,从而积累标注数据不断优化模型生成效果。













专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复或发消息“MD18” 就可以获取《【ChatGPT系列报告】解析Midjourney的成长之路》专知下载链接
 专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai,获取100000+AI(AI与军事、医药、公安等)主题干货知识资料!
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai,获取100000+AI(AI与军事、医药、公安等)主题干货知识资料! 欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程资料和与专家交流咨询!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程资料和与专家交流咨询! 点击“阅读原文”,了解使用专知,查看获取100000+AI主题知识资料
点击“阅读原文”,了解使用专知,查看获取100000+AI主题知识资料