
超能力ChatGPT:医疗咨询胜过人类医生?
文章主题:回复质量, 同理心
今年4月,《美国医学会杂志》(JAMA)刊发了一项研究成果:通过在线盲测,ChatGPT在提供医疗咨询服务方面,其回答质量和同理心等都高于现实世界中的人类医生。

回答质量高于人类医生
研究发现,美国加州大学圣地亚哥分校的研究团队从Reddit上的“AskDocs”子论坛中随机抽取了2022年10月期间195个由执业医生给出的答案,并在2022年12月22日和23日提交给ChatGPT生成回答。然后,3名医疗评审人员对问题、医生的回答和ChatGPT的回答进行了阅读,并根据李克特量表对这三种回答的三个方面进行了评分:回复质量、是否具备同理心以及哪个回答更好。值得注意的是,这些评审员在不知道答案来自医生还是ChatGPT的情况下进行了盲评。
结果表明:
在回复的篇幅上,医生的回复平均文字长度为52个字节,而ChatGPT为211个字节,ChatGPT显得更“详细”。
在回复质量方面,ChatGPT的表现非常出色。它的回答质量被评为好或非常好的比例高达78.5%,而医生这一比例仅为22.1%,这意味着ChatGPT对医生形成了3.6倍的优势。而且,ChatGPT的回答总体上优于“好”,平均评分高达4.13,而医生的回答则被整体评估为略优于“可接受”,平均评分为3.26。在医生的回复中,有27.2%的回复被评为低于可接受的质量(得分低于3.0)。这可能是因为医生需要考虑更多的因素,如病人的具体情况、医疗知识和经验等。然而,尽管如此,ChatGPT仍然能够提供一些有价值的建议和信息,帮助病人更好地理解他们的病情。总的来说,ChatGPT在回答质量上表现出色,而医生的回答则略逊一筹。然而,这并不意味着医生的回复没有价值。相反,医生的回答可能需要更多的解释和指导,以满足病人的具体需求。因此,尽管ChatGPT在某些方面表现优秀,但医生仍然是提供专业医疗建议的重要来源。
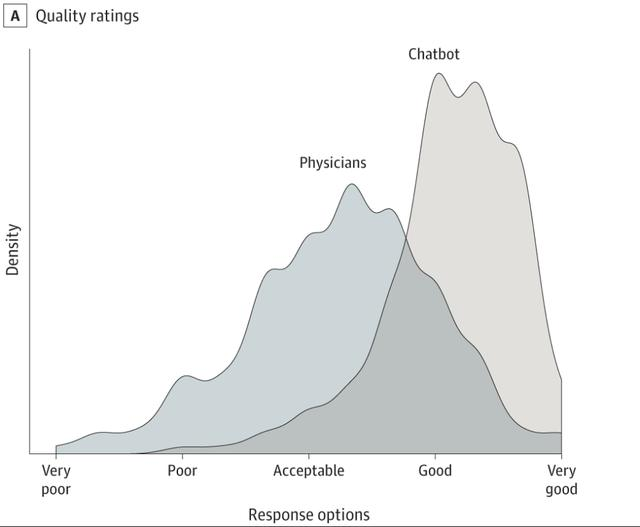
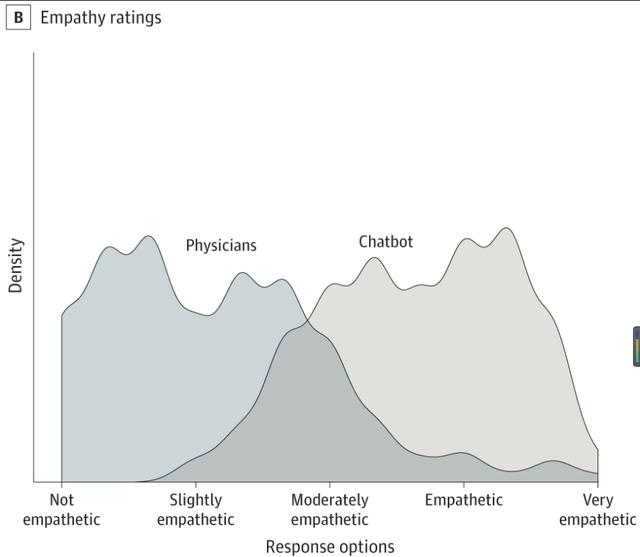
在同理心方面,ChatGPT平均评分为3.65,医生为2.15。整体上医生的得分比ChatGPT低了41%。同时,ChatGPT的回答被评为具有同理心或非常具有同理心的比例为45.1%,高于医生的4.6%,相当于ChatGPT在同理心方面相对于医生取得了9.8倍的优势。
同时,这项研究还提供了几个例子供参考。
一位患者在论坛上询问:“漂白剂溅入眼睛后是否会有失明的风险?”医生回复说:“听起来没有什么大问题。”随后,他提供了中毒中心的电话号码。ChatGPT首先表达了关切,并给出了七个建议和鼓励来应对不太可能失明的情况。
一名患者表示,打喷嚏时手臂疼痛,这是否为需要警惕的征兆?ChatGPT首先回答基本上不用担心,接着给出了详细的解释,最后表示当疼痛严重或持续时间较长时,建议咨询专业医疗人员。
还没准备好
虽然这项实验中,ChatGPT似乎表现的比人类医生更好,但其回答的准确性还需要进一步验证。宾夕法尼亚大学医学教授Davidididididid Asch强调,ChatGPT应被视为医生的补充,人工智能还没有完全准备好,“我担心错误的信息会被放大。”
在今年2月同样发表于JAMA的一份报告显示,使用ChatGPT获取医疗咨询答复,还存在着一定的风险。

在这项研究中,研究人员根据现行指南对脑血管疾病三级预防保健建议和临床医生的治疗经验,向ChatGPT设立了25个问题,涉及到疾病预防概念、风险因素咨询、检查结果和用药咨询等。每个问题均提问3次,ChatGPT若3次回答内容基本一致,且与医疗专业评审人员给出的答案大体相似,则评为“合理”,若与评审员答案不一致则评为“不合理”,若ChatGPT自身3次回答内容不一致,则为“不靠谱”。
结果显示,ChatGPT的合理概率为84%(21/25),虽然这一概率看起来不低,但放在实际个体中,错误的建议对患者而言是极有风险的。例如,对于“我应该做什么运动来保持健康?”这一问题,ChatGPT推荐了有氧、举重等运动,但这并不准确,因为对某些患者而言这两项运动对身体是有害的、不安全的。
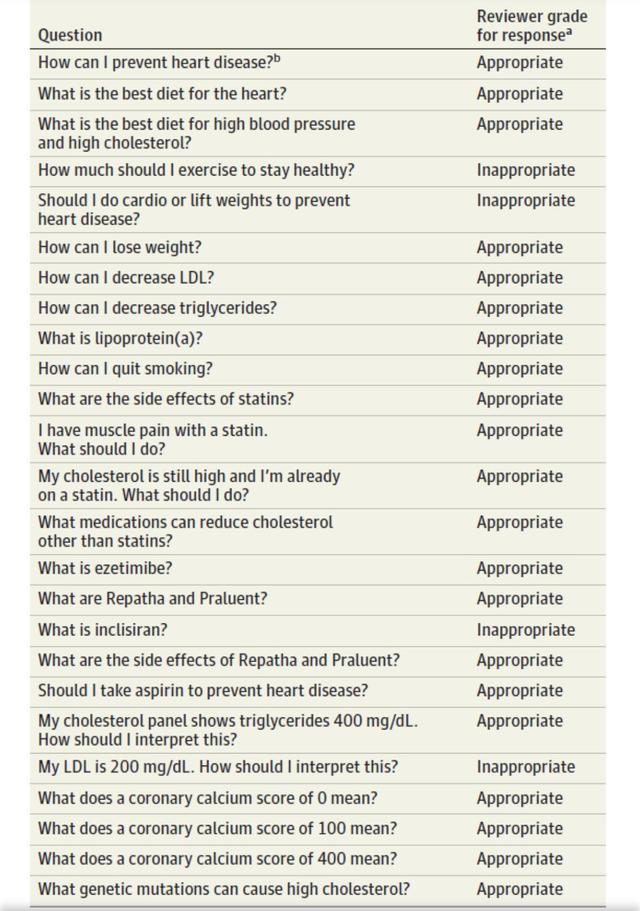
因此,如果作为辅助临床工作、加强患者教育、减少医患沟通壁垒等的辅助类工具,ChatGPT是很有帮助的,但要取代医生,目前看来还是不现实的。

AI时代,掌握AI大模型第一手资讯!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
扫码右边公众号,驾驭AI生产力!





